Conteúdo
O que é árvore de decisão?
17 min
Tutorial sobre árvore de decisão: como fazer a sua própria com o Lucidchart
Primeiros passos no Lucidchart
Modelos de árvores de decisão
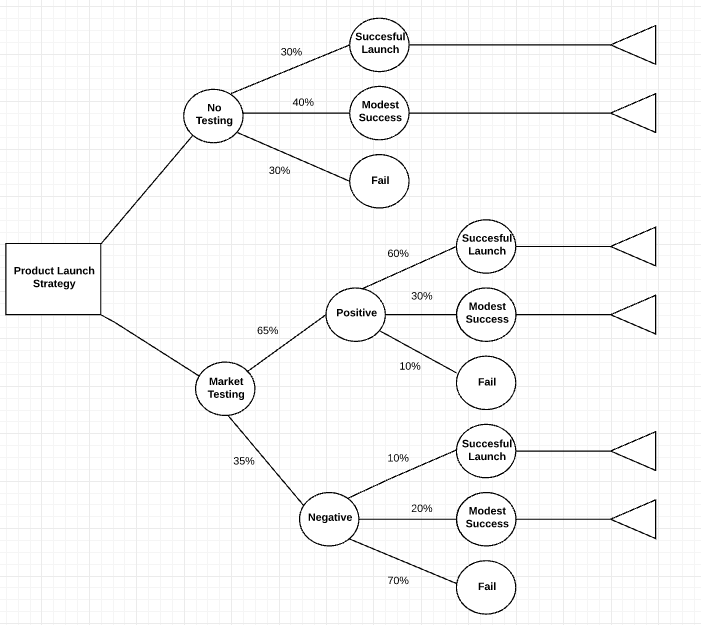
Exemplo de árvore de decisão vertical
Preços:
Conta paga
Exemplo de árvore de decisão vertical, Preços: Conta paga
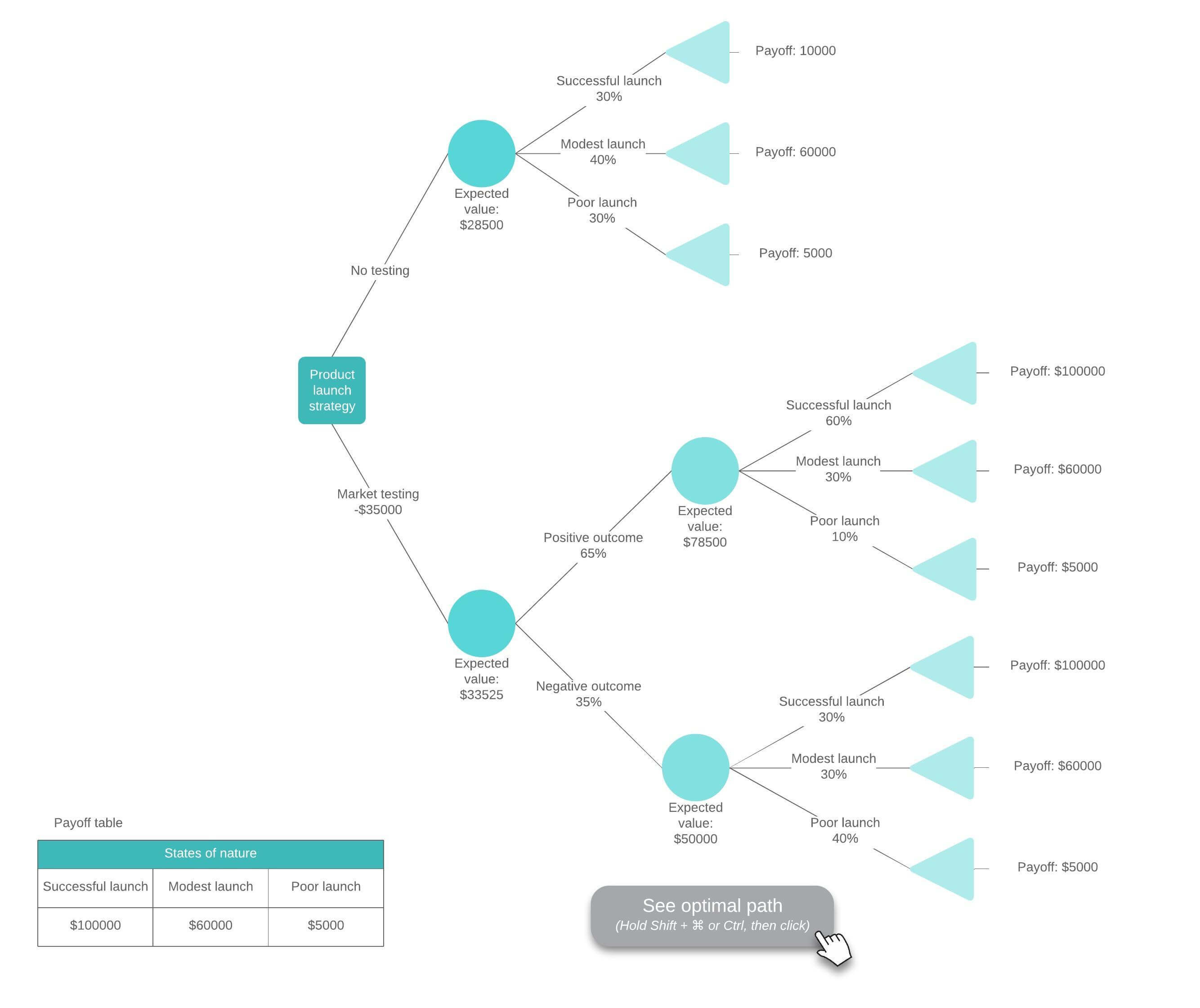
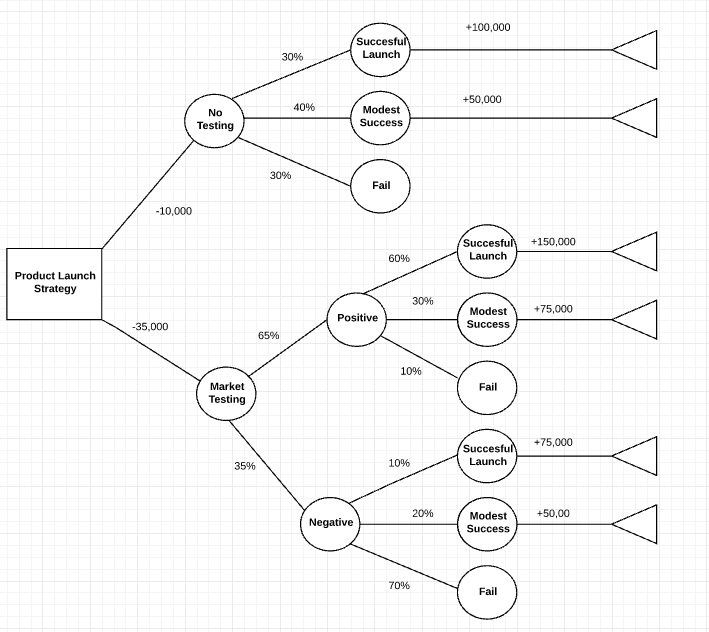
Exemplo de árvore de decisão com fórmulas
Preços:
Conta paga
Exemplo de árvore de decisão com fórmulas, Preços: Conta paga
Recursos de árvore de decisão
Como fazer um diagrama de árvore de decisão no Google Docs
Use este guia para aprender duas formas de fazer uma árvore de decisão no Google Docs.
Como fazer uma árvore de decisão no Word
Para facilitar esse processo, siga nosso guia passo a passo para inserir rapidamente uma árvore de decisão profissional usando o complemento do Lucidchart para Microsoft, ou crie uma árvore de decisão manualmente no MS Word.
Árvore de decisão online
Nosso software de árvore de decisão online torna simples mapear os resultados potenciais de uma série de decisões, esclarecendo as opções, os riscos, os objetivos e os ganhos ou perdas potenciais.
Perguntas frequentes sobre árvores de decisão
O que é árvore de decisão?
Como faço para criar um diagrama de árvore de decisão?
Quais são os principais componentes de uma árvore de decisão?
Quando devo usar um diagrama de árvore de decisão?
Como as árvores de decisão ajudam nas decisões complexas?
Que tipos de problemas as árvores de decisão podem resolver?
Por que uma árvore de decisão é chamada de "árvore"?
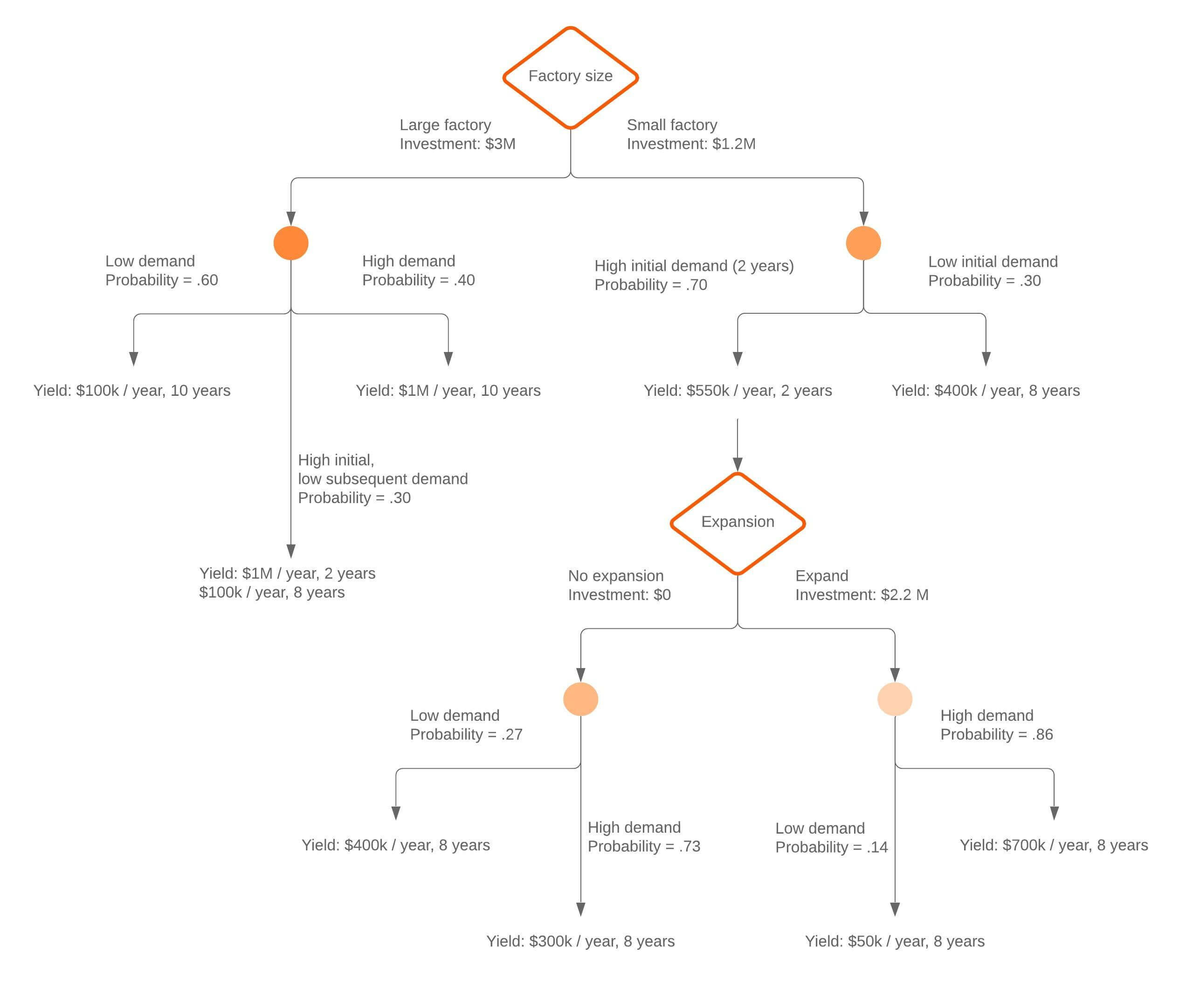
Posso adicionar dados ou fórmulas à minha árvore de decisão?
O Lucidchart tem exemplos de árvore de decisão?
Tudo o que você precisa para criar um diagrama
Além do nosso gerador de diagramas online, o Lucidchart oferece recursos de suporte e treinamento para ajudar você a trabalhar com qualquer tipo de diagrama.
Ver oficina de treinamentos