Vereistenanalyse: het doel van de database bepalen
Als je het doel van je database begrijpt, kun je betere keuzes maken tijdens het ontwerpproces. Bekijk de database zeker vanuit elk perspectief. Als je bijvoorbeeld een database maakt voor een openbare bibliotheek, wil je nadenken over de manieren waarop zowel bezoekers als bibliothecarissen toegang moeten krijgen tot de gegevens.
Hier zijn enkele manieren om informatie te verzamelen voordat je de database maakt:
- Interview de mensen die de database gaan gebruiken
- Analyseer bedrijfsformulieren, zoals facturen, urenstaten en enquêtes
- Spit bestaande gegevenssystemen door (inclusief fysieke en digitale bestanden)
Begin met het verzamelen van alle bestaande gegevens die in de database moeten worden opgenomen. Maak vervolgens een lijst van de soorten gegevens die je wilt opslaan en de entiteiten, ofwel personen, objecten, locaties en gebeurtenissen die door die gegevens worden beschreven, zoals dit:
Klanten
- Naam
- Adres
- Plaats, Provincie, Postcode
- E-mailadres
Producten
- Naam
- Prijs
- Aantal op voorraad
- Aantal in bestelling
Bestellingen
- Bestellings-ID
- Verkoopmedewerker
- Datum
- Product(en)
- Aantal
- Prijs
- Totaal
Deze informatie wordt later onderdeel van de datadictionary, die de tabellen en velden binnen de database beschrijft. Zorg ervoor dat je de informatie opsplitst in de kleinste bruikbare delen. Overweeg bijvoorbeeld om de straatnaam en het land van elkaar te scheiden, zodat je later personen kunt filteren op hun woonland. Voorkom ook dat je hetzelfde gegevenspunt in meer dan één tabel plaatst, want dat zorgt voor onnodige complexiteit.
Zodra je weet welke soorten gegevens de database zal bevatten, waar die gegevens vandaan komen en hoe ze worden gebruikt, ben je klaar om de daadwerkelijke database te gaan plannen.
Databasestructuur: de bouwstenen van een database
De volgende stap is het opzetten van een visuele weergave van je database. Om dat te doen, moet je precies begrijpen hoe relationele databases zijn gestructureerd.
Binnen een database worden gerelateerde gegevens gegroepeerd in tabellen, die elk bestaan uit rijen (ook wel tupels genoemd) en kolommen, net als in een spreadsheet.
Om je lijsten met gegevens om te zetten in tabellen, begin je met het maken van een tabel voor elk type entiteit, zoals producten, verkopen, klanten en bestellingen. Hier is een voorbeeld:
Elke rij in een tabel wordt een record genoemd. Records bevatten gegevens over iets of iemand, zoals een specifieke klant. Kolommen (ook wel velden of attributen genoemd) bevatten daarentegen één type informatie dat in elk record voorkomt, zoals de adressen van alle klanten in de tabel.
| Voornaam | Achternaam | Leeftijd | Postcode |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Om de gegevens consistent te houden van het ene record naar het volgende, wijs je het juiste datatype toe aan elke kolom. Veelvoorkomende datatypes zijn:
- CHAR - tekst met een vaste lengte
- VARCHAR - tekst met een variabele lengte
- TEXT - grote hoeveelheden tekst
- INT - positief of negatief geheel getal
- FLOAT, DOUBLE - kan ook getallen met zwevende komma opslaan
- BLOB - binaire gegevens
Sommige databasebeheersystemen bieden ook het datatype Autonumber, dat automatisch een uniek nummer genereert in elke rij.
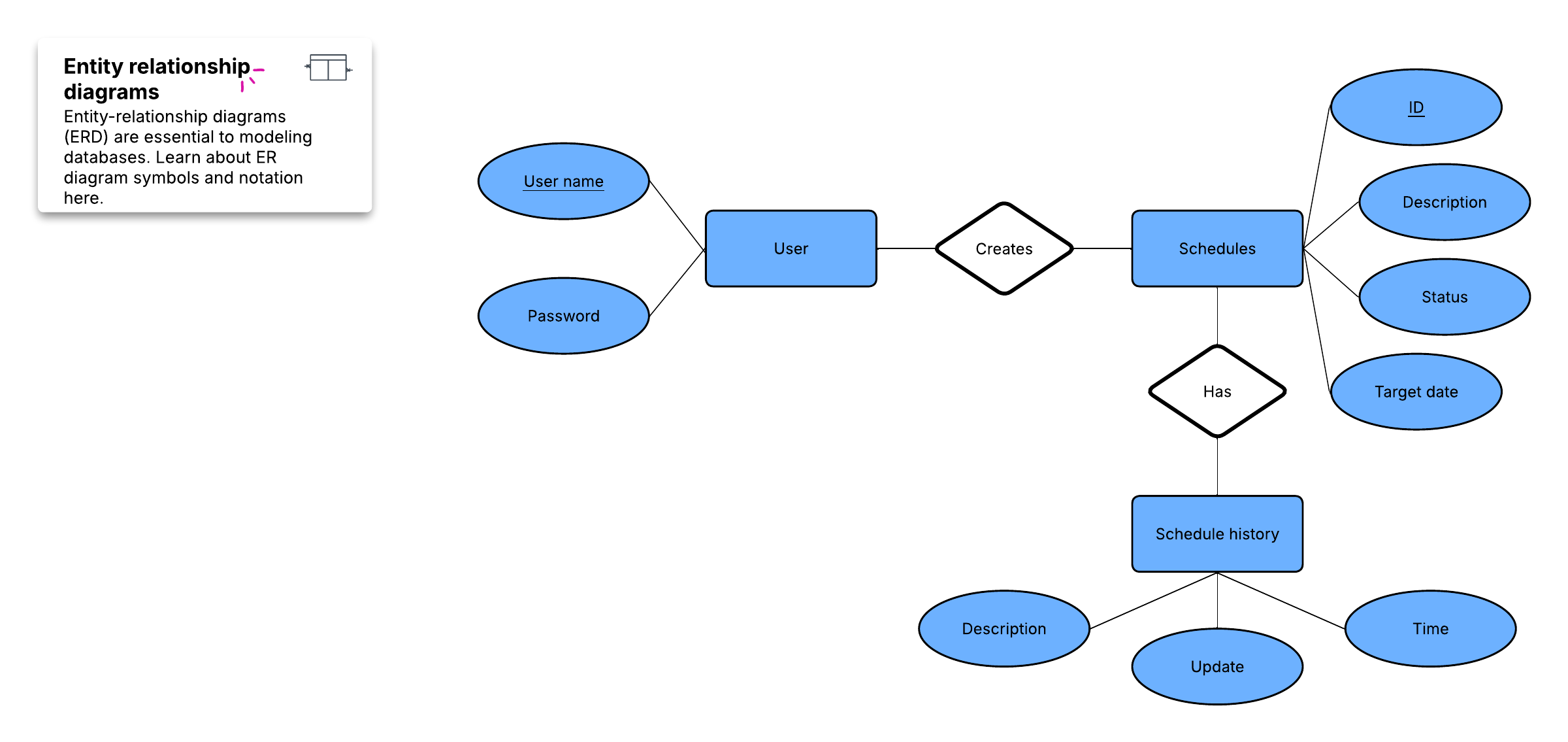
Voor het maken van een visueel overzicht van de database, een zogenaamd entity-relationship diagram, neem je de daadwerkelijke tabellen niet op. In plaats daarvan wordt elke tabel een vak in het diagram. De titel van elk vak moet aangeven wat de gegevens in die tabel beschrijven, terwijl de attributen eronder worden vermeld, zoals dit:

Ten slotte moet je beslissen welke attribuut of attributen als primaire sleutel voor elke tabel gaan dienen, indien van toepassing. Een primaire sleutel (PK) is een unieke identificatie voor een bepaalde entiteit. Dit betekent dat je een exacte klant kunt selecteren, zelfs als je alleen die waarde weet.
Attributen die als primaire sleutel worden gekozen, moeten uniek en onveranderlijk zijn en altijd aanwezig zijn (nooit NULL of leeg). Om deze reden zijn bestelnummers en gebruikersnamen goede primaire sleutels, terwijl telefoonnummers of straatnamen dat niet zijn. Je kunt ook meerdere velden in combinatie gebruiken als primaire sleutel (dit wordt een samengestelde sleutel genoemd).
Wanneer het tijd is om de daadwerkelijke database te maken, zet je zowel de logische gegevensstructuur als de fysieke gegevensstructuur om in de datadefinitietaal die wordt ondersteund door je databasebeheersysteem. Op dat moment moet je ook een schatting maken van de omvang van de database om er zeker van te zijn dat je het prestatieniveau en de opslagruimte krijgt die nodig zijn.
Relaties tussen entiteiten creëren
Nu je databasetabellen zijn omgezet in tabellen, ben je klaar om de relaties tussen die tabellen te analyseren. Cardinaliteit verwijst naar de hoeveelheid elementen die interactie hebben tussen twee gerelateerde tabellen. Het identificeren van de cardinaliteit helpt ervoor te zorgen dat je de gegevens zo efficiënt mogelijk in tabellen hebt verdeeld.
Elke entiteit kan in principe een relatie hebben met elke andere entiteit, maar die relaties vallen meestal binnen een van deze drie typen:
Eén-op-één-relaties
Wanneer er slechts één exemplaar van Entiteit A is voor elk exemplaar van Entiteit B, is er sprake van een één-op-één-relatie (vaak geschreven als 1:1). Je kunt dit soort relatie in een ER-diagram aangeven met een lijn met een streepje aan elk uiteinde:

Tenzij je een goede reden hebt om dit niet te doen, geeft een 1:1-relatie meestal aan dat je de gegevens van de twee tabellen beter kunt combineren in één enkele tabel.
Onder specifieke omstandigheden wil je echter wel tabellen met een 1:1-relatie maken. Als je een veld hebt met optionele gegevens, zoals 'beschrijving', dat voor veel records leeg is, kun je alle beschrijvingen verplaatsen naar een eigen tabel. Zo elimineer je lege ruimte en verbeter je de databaseprestaties.
Om te garanderen dat de gegevens correct overeenkomen, moet je vervolgens ten minste één identieke kolom in elke tabel opnemen, waarschijnlijk de primaire sleutel.
Eén-op-veel-relaties
Deze relaties komen voor wanneer een record in de ene tabel is gekoppeld aan meerdere vermeldingen in een andere tabel. Eén klant kan bijvoorbeeld veel bestellingen hebben geplaatst, of een lener kan meerdere boeken tegelijkertijd uit de bibliotheek hebben geleend. Eén-op-veel-relaties (1:M) worden aangegeven met de zogenaamde 'kraaienpootnotatie', zoals in dit voorbeeld:

Om een 1:M-relatie te implementeren bij het opzetten van een database, voeg je eenvoudigweg de primaire sleutel van de 'één'-kant van de relatie toe als een attribuut in de andere tabel. Wanneer een primaire sleutel op deze manier in een andere tabel wordt vermeld, wordt dit een vreemde sleutel genoemd. De tabel aan de '1'-kant van de relatie wordt beschouwd als een bovenliggende tabel voor de onderliggende tabel aan de andere kant.
Veel-op-veel-relaties
Wanneer meerdere entiteiten uit een tabel kunnen worden gekoppeld aan meerdere entiteiten in een andere tabel, hebben ze een veel-op-veel-relatie (M:N). Dit kan bijvoorbeeld het geval zijn bij studenten en vakken, aangezien een student veel vakken kan volgen en een vak veel studenten kan hebben.
In een ER-diagram worden deze relaties weergegeven met deze lijnen:

Helaas is het niet direct mogelijk om dit soort relaties in een database te implementeren. In plaats daarvan moet je deze opsplitsen in twee één-op-veel-relaties.
Om dit te doen, maak je een nieuwe entiteit tussen die twee tabellen. Als de M:N-relatie bestaat tussen verkopen en producten, kun je die nieuwe entiteit 'verkochte_producten' noemen, omdat deze de inhoud van elke verkoop toont. Zowel de verkoop- als de productentabel hebben dan een 1:M-relatie met verkochte_producten. Dit soort tussenliggende entiteit wordt in verschillende modellen een koppeltabel, associatieve entiteit of kruistabel genoemd.
Elk record in de koppeltabel brengt twee van de entiteiten in de aangrenzende tabellen samen (het kan ook aanvullende informatie bevatten). Een koppeltabel tussen studenten en vakken kan er bijvoorbeeld zo uitzien:

Verplicht of niet?
Een andere manier om relaties te analyseren is door te kijken welke kant van de relatie moet bestaan om de andere kant te laten bestaan. De niet-verplichte kant kan worden gemarkeerd met een cirkel op de lijn waar anders een streepje zou staan. Een land moet bijvoorbeeld bestaan om een vertegenwoordiger in de Verenigde Naties te hebben, maar het omgekeerde is niet waar:

Twee entiteiten kunnen ook wederzijds afhankelijk zijn (de ene kan niet bestaan zonder de andere).
Recursieve relaties
Soms verwijst een tabel naar zichzelf. Een tabel met werknemers kan bijvoorbeeld een attribuut 'manager' hebben dat verwijst naar een andere persoon in diezelfde tabel. Dit noemen we een recursieve relatie.
Redundante relaties
Een redundante relatie is een relatie die meer dan eens wordt uitgedrukt. Meestal kun je een van de relaties verwijderen zonder belangrijke informatie te verliezen. Als een entiteit 'studenten' bijvoorbeeld een directe relatie heeft met een andere entiteit genaamd 'docenten', maar ook een indirecte relatie heeft met docenten via 'vakken', wil je de relatie tussen 'studenten' en 'docenten' verwijderen. Het is beter om die relatie te verwijderen, omdat studenten alleen via vakken aan docenten worden toegewezen.
Databasenormalisatie
Zodra je een voorlopig ontwerp voor je database hebt, kun je normalisatieregels toepassen om te controleren of de tabellen correct zijn gestructureerd. Zie deze regels als de industriestandaarden.
Toch zijn niet alle databases goede kandidaten voor normalisatie. In het algemeen moeten OLTP-databases (Online Transaction Processing), waarin gebruikers records maken, lezen, bijwerken en verwijderen, worden genormaliseerd.
OLAP-databases (Online Analytical Processing) die de voorkeur geven aan analyse en rapportage, presteren mogelijk beter met een zekere mate van denormalisatie, omdat hier de nadruk ligt op de snelheid van berekeningen. Denk hierbij aan toepassingen voor beslissingsondersteuning waarin gegevens snel moeten worden geanalyseerd, maar niet gewijzigd.
Elke vorm of elk niveau van normalisatie bevat de regels die horen bij de lagere vormen.
Eerste normaalvorm
De eerste normaalvorm (afgekort als 1NF) schrijft voor dat elke cel in de tabel slechts één waarde mag bevatten, nooit een lijst met waarden. Een tabel als deze voldoet dus niet:
| ProductID | Kleur | Prijs |
|---|
| 1 | bruin, geel | $15 |
| 2 | rood, groen | $13 |
| 3 | blauw, oranje | $11 |
Je bent misschien geneigd om dit te omzeilen door die gegevens op te splitsen in extra kolommen, maar dat is ook tegen de regels: een tabel met groepen herhaalde of nauw verwante attributen voldoet niet aan de eerste normaalvorm. De onderstaande tabel voldoet bijvoorbeeld niet:

Splits in plaats daarvan de gegevens op in meerdere tabellen of records totdat elke cel slechts één waarde bevat en er geen extra kolommen zijn. Op dat moment worden de gegevens atomair genoemd, oftewel afgebroken tot de kleinste bruikbare omvang. Voor de bovenstaande tabel zou je een extra tabel kunnen maken genaamd 'Verkoopdetails' die specifieke producten koppelt aan verkopen. 'Verkopen' heeft dan een 1:M-relatie met 'Verkoopdetails'.
Tweede normaalvorm
De tweede normaalvorm (2NF) vereist dat elk van de attributen volledig afhankelijk is van de gehele primaire sleutel. Dat betekent dat elk attribuut rechtstreeks afhankelijk moet zijn van de primaire sleutel, en niet indirect via een ander attribuut.
Een attribuut 'leeftijd' dat afhankelijk is van 'geboortedatum', dat op zijn beurt weer afhankelijk is van 'studentID', heeft bijvoorbeeld een gedeeltelijke functionele afhankelijkheid. Een tabel met deze attributen voldoet dan niet aan de tweede normaalvorm.
Bovendien schendt een tabel met een primaire sleutel die uit meerdere velden bestaat de tweede normaalvorm als een of meer van de andere velden niet afhankelijk zijn van elk deel van de sleutel.
Een tabel met deze velden zou dus niet voldoen aan de tweede normaalvorm, omdat het attribuut 'productnaam' wel afhankelijk is van het product-ID, maar niet van het bestelnummer:
Derde normaalvorm
De derde normaalvorm (3NF) voegt aan deze regels de eis toe dat elke kolom die geen sleutel is, onafhankelijk moet zijn van elke andere kolom. Als het wijzigen van een waarde in de ene niet-sleutelkolom ertoe leidt dat een andere waarde verandert, voldoet die tabel niet aan de derde normaalvorm.
Dit voorkomt dat je afgeleide gegevens in de tabel opslaat, zoals de onderstaande kolom 'belasting', die rechtstreeks afhankelijk is van de totale prijs van de bestelling:
| Bestelling | Prijs | Belasting |
|---|
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Er zijn nog aanvullende vormen van normalisatie voorgesteld, waaronder de Boyce-Codd-normaalvorm, de vierde tot en met de zesde normaalvorm en de domeinsleutel-normaalvorm, maar de eerste drie komen het meest voor.
Hoewel deze vormen de algemene best practices uitleggen, hangt de mate van normalisatie af van de context van de database.
Multidimensionale gegevens
Sommige gebruikers willen toegang tot meerdere dimensies van één type gegevens, met name in OLAP-databases. Ze willen bijvoorbeeld de verkoop per klant, provincie en maand weten. In deze situatie kun je het beste een centrale feitentabel maken waarnaar andere klant-, provincie- en maandtabellen kunnen verwijzen, zoals dit:

Regels voor gegevensintegriteit
Je moet je database ook zo configureren dat de gegevens worden gevalideerd volgens de juiste regels. Veel databasebeheersystemen, zoals Microsoft Access, dwingen sommige van deze regels automatisch af.
De entiteitsintegriteitsregel stelt dat de primaire sleutel nooit NULL mag zijn. Als de sleutel uit meerdere kolommen bestaat, mag geen van deze kolommen NULL zijn. Anders kan de regel mislukken om het record uniek te identificeren.
De referentiële integriteitsregel vereist dat elke vreemde sleutel in de ene tabel overeenkomt met één primaire sleutel in de tabel waarnaar wordt verwezen. Als de primaire sleutel verandert of wordt verwijderd, moeten die wijzigingen overal worden doorgevoerd waar naar die sleutel wordt verwezen in de database.
Bedrijfslogica-integriteitsregels zorgen ervoor dat de gegevens binnen bepaalde logische parameters passen. Een afspraaktijd zou bijvoorbeeld binnen de normale kantooruren moeten vallen.
Indexen en weergaven toevoegen
Een index is in feite een gesorteerde kopie van een of meer kolommen, waarbij de waarden in oplopende of aflopende volgorde staan. Door een index toe te voegen, kunnen gebruikers records sneller vinden. In plaats van voor elke query opnieuw te sorteren, heeft het systeem direct toegang tot records in de volgorde die door de index is gespecificeerd.
Hoewel indexen het ophalen van gegevens versnellen, kunnen ze het invoegen, bijwerken en verwijderen vertragen, omdat de index telkens opnieuw moet worden opgebouwd wanneer een record wordt gewijzigd.
Een weergave is simpelweg een opgeslagen query op de gegevens. Ze kunnen handig zijn om gegevens uit meerdere tabellen samen te voegen of om een deel van een tabel te tonen.
Uitgebreide eigenschappen
Zodra je de basislay-out hebt voltooid, kun je de database verfijnen met uitgebreide eigenschappen, zoals instructietekst, invoermaskers en opmaakregels die van toepassing zijn op een specifiek schema, een specifieke weergave of kolom. Het voordeel hiervan is dat, omdat deze regels in de database zelf worden opgeslagen, de weergave van de gegevens consistent blijft over de verschillende programma's die toegang hebben tot de gegevens.
SQL en UML
De Unified Modeling Language (UML) is een andere visuele manier om complexe systemen uit te drukken die zijn gemaakt in een objectgeoriënteerde taal. Verschillende concepten die in deze handleiding worden genoemd, staan in UML bekend onder andere namen. Een entiteit staat in UML bijvoorbeeld bekend als een klasse.
UML wordt tegenwoordig niet meer zo vaak gebruikt als vroeger. Tegenwoordig wordt het vooral academisch gebruikt en in de communicatie tussen softwareontwerpers en hun klanten.
Databasebeheersystemen
Veel van de ontwerpkeuzes die je maakt, hangen af van het databasebeheersysteem dat je gebruikt. Enkele van de meest voorkomende systemen zijn:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Wanneer je de keuze hebt, kies dan een geschikt databasebeheersysteem op basis van kosten, besturingssystemen, functies en meer.
Schema in Oracle Database-systeem
In het Oracle-databasesysteem heeft de term databaseschema, die ook wel bekendstaat als 'SQL-schema', een andere betekenis. Hier kan een database meerdere schema's hebben. Elk schema bevat alle objecten die door een specifieke databasegebruiker zijn gemaakt. Die objecten kunnen tabellen, weergaven, synoniemen en meer omvatten. Sommige objecten kunnen niet in een schema worden opgenomen, zoals gebruikers, contexten, rollen en directory-objecten.

Gebruikers kunnen per geval toegang krijgen om in te loggen op individuele schema's, en het eigendom is overdraagbaar. Omdat elk object gekoppeld is aan een specifiek schema, dat dient als een soort naamruimte, is het handig om synoniemen te gebruiken. Hiermee kunnen andere gebruikers toegang krijgen tot dat object zonder eerst te hoeven verwijzen naar het schema waartoe het behoort.
Deze schema's geven niet noodzakelijkerwijs aan hoe de gegevensbestanden fysiek worden opgeslagen. In plaats daarvan worden schema-objecten logisch opgeslagen binnen een tablespace. De databasebeheerder kan opgeven hoeveel ruimte aan een specifiek object binnen een gegevensbestand moet worden toegewezen.
Ten slotte lopen schema's en tablespaces niet per se perfect synchroon: objecten uit één schema kunnen in meerdere tablespaces voorkomen, terwijl een tablespace objecten uit meerdere schema's kan bevatten.
Database-instantie of databaseschema?
Hoewel deze termen aan elkaar verwant zijn, betekenen ze niet hetzelfde. Een databaseschema is een blauwdruk van een geplande database. Het bevat nog geen daadwerkelijke gegevens.
Een database-instantie is daarentegen een momentopname van een database zoals deze op een specifiek tijdstip bestond. Database-instanties kunnen in de loop van de tijd dus veranderen, terwijl een databaseschema meestal statisch is. Het is namelijk ingewikkeld om de structuur van een database te wijzigen zodra deze operationeel is.
Databaseschema's en database-instanties kunnen elkaar beïnvloeden via een databasebeheersysteem (DBMS). Het DBMS zorgt ervoor dat elke database-instantie voldoet aan de beperkingen die de databaseontwerpers in het databaseschema hebben vastgelegd.
Vereisten voor schema-integratie
Het kan handig zijn om meerdere bronnen in één schema te integreren. Zorg ervoor dat aan deze vereisten wordt voldaan voor een naadloze overgang:
Behoud van overlapping
Elk overlappend element in de schema's die je integreert, moet zich in een tabel van het databaseschema bevinden.
Uitgebreid behoud van overlapping
Elementen die slechts in één bron voorkomen, maar die gekoppeld zijn aan overlappende elementen, moeten worden gekopieerd naar het resulterende databaseschema.
Normalisatie
Onafhankelijke relaties en entiteiten mogen niet samen in dezelfde tabel in het databaseschema worden geplaatst.
Minimaliteit
Het is ideaal als er geen enkel element uit de bronnen verloren gaat.
Typen databaseschema's
Er zijn bepaalde patronen ontstaan bij het ontwerpen van databaseschema's.
Het veelgebruikte sterschema is ook meteen het eenvoudigst. Hierin zijn een of meer feitentabellen gekoppeld aan een willekeurig aantal dimensietabellen. Dit schema is het meest geschikt voor het verwerken van eenvoudige query's.
Het verwante sneeuwvlokschema wordt ook gebruikt om een multidimensionale database weer te geven. In dit patroon worden dimensies echter genormaliseerd in tal van afzonderlijke tabellen, wat het effect geeft van een structuur die lijkt op een sneeuwvlok.