Analisi dei requisiti: identificare lo scopo del database
Comprendere lo scopo del database guiderà le tue scelte durante l'intero processo di progettazione. Assicurati di considerare il database da ogni prospettiva. Ad esempio, se stai creando un database per una biblioteca pubblica, dovrai considerare i modi in cui sia gli utenti sia i bibliotecari dovranno accedere ai dati.
Ecco alcuni modi per raccogliere informazioni prima di creare il database:
- Intervista le persone che lo utilizzeranno
- Analizza i moduli aziendali, come fatture, fogli presenze, sondaggi
- Esamina i sistemi di dati esistenti (inclusi i file fisici e digitali)
Inizia raccogliendo tutti i dati esistenti che saranno inclusi nel database. Elenca poi i tipi di dati che desideri archiviare e le entità (ovvero persone, cose, luoghi ed eventi) descritte da tali dati, in questo modo:
Clienti
- Nome
- Indirizzo
- Città, Stato, CAP
- Indirizzo e-mail
Prodotti
- Nome
- Prezzo
- Quantità in magazzino
- Quantità in ordinazione
Ordini
- ID ordine
- Agente di vendita
- Data
- Prodotti
- Quantità
- Prezzo
- Totale
Queste informazioni faranno poi parte del dizionario dei dati, che delinea le tabelle e i campi all'interno del database. Assicurati di scomporre le informazioni in parti minime e utili. Ad esempio, valuta la possibilità di separare l'indirizzo stradale dal paese in modo da poter filtrare in un secondo momento le persone in base al loro paese di residenza. Inoltre, evita di inserire lo stesso punto dati in più di una tabella, per non aggiungere inutili complessità.
Una prima conoscenza dei tipi di dati che il database includerà, della loro provenienza e del modo in care verranno utilizzati ti consentirà di iniziare a pianificare il database vero e proprio.
Struttura del database: i mattoncini di un database
Il passo successivo consiste nel definire una rappresentazione visiva del database. Per farlo, devi capire esattamente come sono strutturati i database relazionali.
All'interno di un database, i dati correlati sono raggruppati in tabelle, ognuna delle quali è composta da righe (chiamate anche tuple) e colonne, proprio come un foglio di calcolo.
Per convertire i tuoi elenchi di dati in tabelle, inizia creando una tabella per ogni tipo di entità, come prodotti, vendite, clienti e ordini. Ecco un esempio:
Ogni riga di una tabella è chiamata record. I record includono dati su qualcosa o qualcuno, ad esempio un cliente specifico. Al contrario, le colonne (note anche come campi o attributi) contengono un unico tipo di informazione che compare in ogni record, come gli indirizzi di tutti i clienti elencati nella tabella.
| Nome | Cognome | Età | CAP |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Per mantenere i dati coerenti da un record all'altro, assegna il tipo di dati appropriato a ciascuna colonna. I tipi di dati comuni includono:
- CHAR - una lunghezza specifica di testo
- VARCHAR - testo di lunghezza variabile
- TEXT - grandi quantità di testo
- INT - numero intero positivo o negativo
- FLOAT, DOUBLE - possono memorizzare anche numeri a virgola mobile
- BLOB - dati binari
Alcuni sistemi di gestione di database offrono anche il tipo di dati Autonumber, che genera automaticamente un numero univoco in ogni riga.
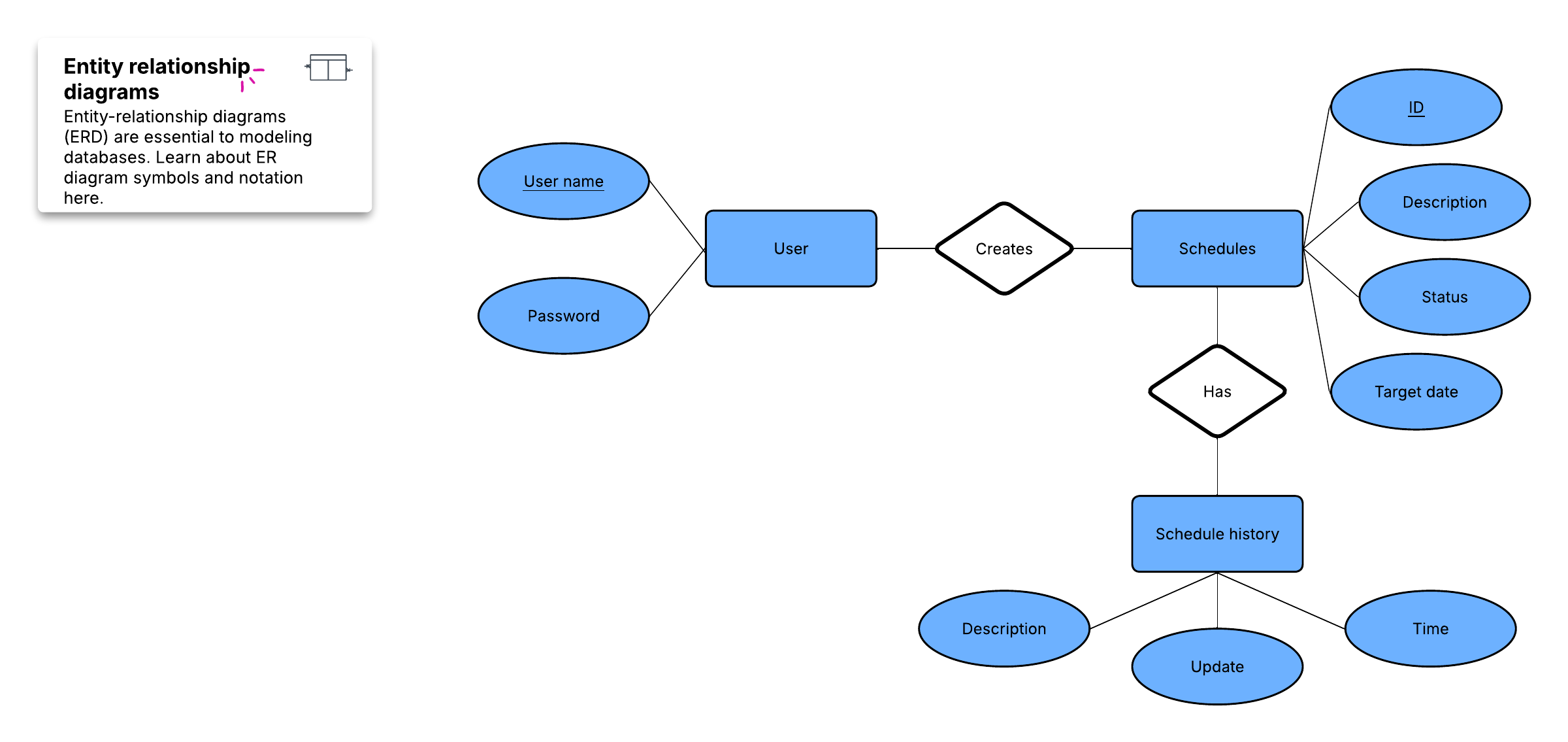
Per creare una panoramica visiva del database, nota come diagramma entità-relazione, non includerai le tabelle effettive. Al contrario, ogni tabella diventa una casella nel diagramma. Il titolo di ciascuna casella deve indicare l'oggetto dei dati di quella tabella, mentre gli attributi sono elencati sotto, in questo modo:

Infine, devi decidere quale o quali attributi fungeranno da chiave primaria per ciascuna tabella, se presenti. Una chiave primaria (PK) è un identificatore univoco per una determinata entità, il che significa che potresti individuare un cliente esatto anche se conoscessi solo quel valore.
Gli attributi scelti come chiavi primarie devono essere univoci, immutabili e sempre presenti (mai NULL o vuoti). Per questo motivo, i numeri d'ordine e i nomi utente sono ottime chiavi primarie, mentre i numeri di telefono o gli indirizzi stradali non lo sono. Puoi anche utilizzare più campi insieme come chiave primaria (questa è nota come chiave composta).
Al momento di creare il database vero e proprio, inserirai sia la struttura logica dei dati sia la struttura fisica dei dati nel linguaggio di definizione dei dati supportato dal tuo sistema di gestione del database. A quel punto, dovresti anche stimare le dimensioni del database per essere sicuro di ottenere il livello di prestazioni e lo spazio di archiviazione necessari.
Creazione di relazioni tra entità
Con le tabelle del tuo database ora convertite in tabelle, sei pronto ad analizzare le relazioni tra di esse. La cardinalità si riferisce alla quantità di elementi che interagiscono tra due tabelle correlate. Identificare la cardinalità aiuta a verificare di aver suddiviso i dati nelle tabelle in modo efficiente.
Ogni entità può potenzialmente avere una relazione con ogni altra, ma queste relazioni sono in genere di tre tipi:
Relazioni uno a uno
Quando c'è una sola istanza dell'Entità A per ogni istanza dell'Entità B, si dice che hanno una relazione uno a uno (spesso scritta 1:1). Puoi indicare questo tipo di relazione in un diagramma ER con una linea con un trattino su ciascuna estremità:

A meno che tu non abbia un buon motivo per non farlo, una relazione 1:1 indica solitamente che sarebbe meglio unire i dati delle due tabelle in un'unica tabella.
Tuttavia, potresti voler creare tabelle con una relazione 1:1 in una particolare serie di circostanze. Se hai un campo con dati facoltativi, come "descrizione", che è vuoto per molti record, puoi spostare tutte le descrizioni in una tabella a parte, eliminando lo spazio vuoto e migliorando le prestazioni del database.
Per garantire la corretta corrispondenza dei dati, dovrai includere almeno una colonna identica in ogni tabella, molto probabilmente la chiave primaria.
Relazioni uno a molti
Queste relazioni si verificano quando un record in una tabella è associato a più voci in un'altra. Ad esempio, un singolo cliente potrebbe aver effettuato molti ordini, oppure un utente potrebbe avere più libri in prestito dalla biblioteca contemporaneamente. Le relazioni uno a molti (1:M) sono indicate con la cosiddetta "notazione a zampa di gallina", come in questo esempio:

Per implementare una relazione 1:M durante la configurazione di un database, basta aggiungere la chiave primaria del lato "uno" della relazione come attributo nell'altra tabella. Quando una chiave primaria è elencata in un'altra tabella in questo modo, viene chiamata chiave esterna. La tabella sul lato "1" della relazione è considerata una tabella padre rispetto alla tabella figlio sull'altro lato.
Relazioni molti a molti
Quando più entità di una tabella possono essere associate a più entità di un'altra tabella, si dice che hanno una relazione molti a molti (M:N). Questo potrebbe accadere nel caso di studenti e corsi, poiché uno studente può frequentare molti corsi e un corso può avere molti studenti.
In un diagramma ER, queste relazioni sono raffigurate con queste linee:

Purtroppo non è possibile implementare direttamente questo tipo di relazione in un database. Al contrario, è necessario suddividerla in due relazioni uno a molti.
Per farlo, crea una nuova entità tra queste due tabelle. Se la relazione M:N esiste tra vendite e prodotti, potresti chiamare la nuova entità "prodotti_venduti", poiché mostrerebbe il contenuto di ogni vendita. Sia la tabella delle vendite sia quella dei prodotti avrebbero una relazione 1:M con i prodotti_venduti. Questo tipo di entità intermedia viene chiamata tabella di collegamento, entità associativa o tabella di giunzione nei vari modelli.
Ogni record nella tabella di collegamento abbinerebbe due entità delle tabelle vicine (può includere anche informazioni supplementari). Ad esempio, una tabella di collegamento tra studenti e corsi potrebbe avere questo aspetto:

Obbligatorio o no?
Un altro modo per analizzare le relazioni è considerare quale lato della relazione deve esistere affinché l'altro esista. Il lato non obbligatorio può essere contrassegnato con un cerchio sulla linea in cui si troverebbe un trattino. Ad esempio, un paese deve esistere per avere un rappresentante alle Nazioni Unite, ma non è vero il contrario:

Due entità possono essere reciprocamente dipendenti (l'una non potrebbe esistere senza l'altra).
Relazioni ricorsive
A volte una tabella rimanda a se stessa. Ad esempio, una tabella di dipendenti potrebbe avere un attributo "manager" che si riferisce a un'altra persona della stessa tabella. Questa viene definita relazione ricorsiva.
Relazioni ridondanti
Una relazione ridondante è una relazione espressa più di una volta. In genere, è possibile rimuovere una delle relazioni senza perdere informazioni importanti. Ad esempio, se un'entità "studenti" ha una relazione diretta con un'altra chiamata "insegnanti" ma ha anche una relazione indiretta con gli insegnanti attraverso i "corsi", è consigliabile rimuovere la relazione tra "studenti" e "insegnanti". È meglio eliminare questa relazione perché l'unico modo in cui gli studenti sono assegnati agli insegnanti è attraverso i corsi.
Normalizzazione del database
Una volta ottenuto il progetto preliminare del database, puoi applicare le regole di normalizzazione per assicurarti che le tabelle siano strutturate correttamente. Pensa a queste regole come agli standard del settore.
Detto questo, non tutti i database sono buoni candidati per la normalizzazione. In generale, i database OLTP (Online Transaction Processing), in cui gli utenti si occupano di creare, leggere, aggiornare ed eliminare record, dovrebbero essere normalizzati.
I database OLAP (Online Analytical Processing), che privilegiano l'analisi e la reportistica, potrebbero trarre maggiore vantaggio da un certo grado di denormalizzazione, poiché l'accento è posto sulla velocità di calcolo. Tra queste vi sono le applicazioni di supporto alle decisioni in cui i dati devono essere analizzati rapidamente ma non modificati.
Ogni forma, o livello di normalizzazione, include le regole associate alle forme inferiori.
Prima forma normale
La prima forma normale (abbreviata in 1NF) specifica che ogni cella della tabella può avere un solo valore, mai un elenco di valori, quindi una tabella come questa non è conforme:
| IDProdotto | Colore | Prezzo |
|---|
| 1 | marrone, giallo | $15 |
| 2 | rosso, verde | $13 |
| 3 | blu, arancione | $11 |
Si potrebbe essere tentati di aggirare il problema dividendo i dati in colonne aggiuntive, ma anche questo è contrario alle regole: una tabella con gruppi di attributi ripetuti o strettamente correlati non soddisfa la prima forma normale. La tabella seguente, ad esempio, non è conforme:

Invece, dividi i dati in più tabelle o record finché ogni cella non contiene un solo valore e non ci sono colonne in più. A quel punto, i dati si dicono atomici, ovvero ridotti alla dimensione minima utile. Per la tabella precedente, potresti creare una tabella aggiuntiva chiamata "Dettagli vendite" che abbini prodotti specifici alle vendite. Le "Vendite" avrebbero quindi una relazione 1:M con i "Dettagli vendite".
Seconda forma normale
La seconda forma normale (2NF) impone che ciascuno degli attributi dipenda completamente dall'intera chiave primaria. Ciò significa che ogni attributo deve dipendere direttamente dalla chiave primaria, anziché indirettamente tramite un altro attributo.
Ad esempio, un attributo "età" che dipende da "data di nascita" che a sua volta dipende da "IDstudente" ha una dipendenza funzionale parziale e una tabella contenente questi attributi non soddisferebbe la seconda forma normale.
Inoltre, una tabella con una chiave primaria composta da più campi viola la seconda forma normale se uno o più degli altri campi no dipendono da ogni parte della chiave.
Quindi, una tabella con questi campi non soddisferebbe la seconda forma normale, perché l'attributo "nome del prodotto" dipende dall'ID del prodotto ma non dal numero d'ordine:
Terza forma normale
La terza forma normale (3NF) aggiunge a queste regole il requisito che ogni colonna non chiave sia indipendente da ogni altra colonna. Se la modifica di un valore in una colonna non chiave provoca la modifica di un altro valore, la tabella non soddisfa la terza forma normale.
Questo evita di memorizzare dati derivati nella tabella, come la colonna "tasse" qui sotto, che dipende direttamente dal prezzo totale dell'ordine:
| Ordine | Prezzo | Tasse |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Sono state proposte altre forme di normalizzazione, tra cui la forma normale di Boyce-Codd, dalla quarta alla sesta forma normale e la forma normale del dominio-chiave, ma le prime tre sono le più comuni.
Sebbene queste forme spieghino le migliori pratiche da seguire in generale, il grado di normalizzazione dipende dal contesto del database.
Dati multidimensionali
Alcuni utenti potrebbero voler accedere a più dimensioni di un singolo tipo di dati, in particolare nei database OLAP. Ad esempio, potrebbero voler conoscere le vendite per cliente, stato e mese. In questa situazione, è preferibile creare una tabella dei fatti centrale a cui fare riferimento per le altre tabelle di clienti, stati e mesi, in questo modo:

Regole di integrità dei dati
Dovresti anche configurare il tuo database in modo da convalidare i dati in base alle regole appropriate. Molti sistemi di gestione di database, come Microsoft Access, applicano alcune di queste regole automaticamente.
La regola dell'integrità dell'entità stabilisce que la chiave primaria non può mai essere NULL. Se la chiave è composta da più colonne, nessuna di esse può essere NULL. In caso contrario, potrebbe non riuscire a identificare univocamente il record.
La regola dell'integrità referenziale richiede che ogni chiave esterna elencata in una tabella sia abbinata a una chiave primaria nella tabella a cui fa riferimento. Se la chiave primaria cambia o viene eliminata, tali modifiche dovranno essere implementate ovunque la chiave sia referenziata all'interno del database.
Le regole di integrità della logica aziendale assicurano che i dati rientrino in determinati parametri logici. Ad esempio, l'orario di un appuntamento deve rientrare nel normale orario d'ufficio.
Aggiunta di indici e viste
Un indice è essenzialmente una copia ordinata di una o più colonne, con i valori in ordine crescente o decrescente. L'aggiunta di un indice consente agli utenti di trovare i record più rapidamente. Invece di ordinare nuovamente per ogni query, il sistema può accedere ai record nell'ordine specificato dall'indice.
Sebbene gli indici accelerino il recupero dei dati, possono rallentare l'inserimento, l'aggiornamento e l'eliminazione, poiché l'indice deve essere ricostruito ogni volta che un record viene modificato.
Una vista è semplicemente una query salvata sui dati. Possono unire utilmente i dati di più tabelle o mostrare una parte di una tabella.
Proprietà estese
Una volta completato il layout di base, puoi perfezionare il database con proprietà estese, come testi di istruzioni, maschere di input e regole di formattazione che si applicano a un particolare schema, vista o colonna. Il vantaggio è che, poiché queste regole sono memorizzate nel database stesso, la presentazione dei dati sarà coerente tra i molteplici programmi che accedono ai dati.
SQL e UML
L'Unified Modeling Language (UML) è un altro modo visivo di esprimere sistemi complessi creati in un linguaggio orientato agli oggetti. Diversi concetti menzionati in questa guida sono noti in UML con nomi differenti. Ad esempio, un'entità è nota come classe in UML.
L'UML non è usato oggi così frequentemente come in passato. Oggi viene spesso utilizzato in ambito accademico e nelle comunicazioni tra i progettisti di software e i loro clienti.
Sistemi di gestione di database
Molte delle scelte di progettazione dipendono dal sistema di gestione del database utilizzato. Alcuni dei sistemi più comuni includono:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Quando puoi scegliere, seleziona il sistema di gestione del database appropriato in base ai costi, ai sistemi operativi, alle funzionalità e altro ancora.
Schema nel sistema Oracle Database
Nel sistema di database Oracle, il termine schema di database, noto anche come "schema SQL", ha un significato diverso. In questo caso, un database può avere più schemi (o "schemata", per usare un termine più ricercato). Ognuno di essi contiene tutti gli oggetti creati da uno specifico utente del database. Tali oggetti possono includere tabelle, viste, sinonimi e altro ancora. Alcuni oggetti non possono essere inclusi in uno schema, come gli utenti, i contesti, i ruoli e gli oggetti di directory.

Agli utenti può essere concesso l'accesso ai singoli schemi caso per caso e la proprietà è trasferibile. Poiché ogni oggetto è associato a un particolare schema, che funge da sorta di spazio dei nomi, è utile fornire alcuni sinonimi, che consentono ad altri utenti di accedere a quell'oggetto senza fare prima riferimento allo schema a cui appartiene.
Questi schemi non indicano necessariamente il modo in cui i file di dati sono memorizzati fisicamente. Al contrario, gli oggetti dello schema sono memorizzati logicamente all'interno di un tablespace. L'amministratore del database può specificare lo spazio da assegnare a un particolare oggetto all'interno di un file di dati.
Infine, gli schemi e i tablespace non sono necessariamente allineati perfettamente: gli oggetti di uno schema si possono trovare in più tablespace, mentre un tablespace può includere oggetti di diversi schemi.
Istanza di database o schema di database?
Questi termini, sebbene correlati, non significano la stessa cosa. Uno schema di database è la bozza di un database pianificato. Non contiene dati effettivi.
Un'istanza di database, invece, è l'istantanea di un database così come esisteva in un determinato momento. Pertanto, le istanze di database possono cambiare nel tempo, mentre lo schema di un database è solitamente statico, poiché è difficile cambiare la struttura di un database una volta operativo.
Gli schemi e le istanze di database possono influenzarsi a vicenda attraverso un sistema di gestione di database (DBMS). Il DBMS assicura che ogni istanza di database sia conforme ai vincoli imposti dai progettisti nello schema del database.
Requisiti di integrazione dello schema
Può essere utile integrare più sorgenti in un unico schema. Assicurati che questi requisiti siano soddisfatti per una transizione senza problemi:
Conservazione della sovrapposizione
Ogni elemento sovrapposto negli schemi che stai integrando deve trovarsi in una tabella dello schema del database.
Conservazione della sovrapposizione estesa
Gli elementi che appaiono solo in una sorgente, ma che sono associati a elementi sovrapposti, devono essere copiati nello schema di database risultante.
Normalizzazione
Le relazioni e le entità indipendenti non devono essere raggruppate nella stessa tabella dello schema del database.
Minimalità
L'ideale è che nessuno degli elementi di nessuna delle sorgenti vada perduto.
Tipi di schema di database
Nella progettazione degli schemi di database si sono sviluppati alcuni modelli.
Lo schema a stella, ampiamente utilizzato, è anche il più semplice. In esso, una o più tabelle dei fatti sono collegate a un numero qualsiasi di tabelle dimensionali. È ideale per la gestione di query semplici.
Il relativo schema a fiocco di neve viene utilizzato anche per rappresentare un database multidimensionale. In questo modello, tuttavia, le dimensioni sono normalizzate in molte tabelle separate, creando l'effetto espansivo di una struttura simile a un fiocco di neve.