Analyse des besoins : identifier l'objectif de la base de données
Comprendre l'objectif de votre base de données orientera vos choix tout au long du processus de conception. Veillez à étudier la base de données sous tous les angles. Par exemple, si vous créez une base de données pour une bibliothèque publique, vous devez prendre en compte la manière dont les usagers et les bibliothécaires devront accéder aux données.
Voici quelques moyens de recueillir des informations avant de créer la base de données :
- Interroger les personnes qui l'utiliseront
- Analyser les documents de l'entreprise, tels que les factures, les feuilles de temps, les enquêtes
- Passer au peigne fin les systèmes de données existants (y compris les fichiers physiques et numériques)
Commencez par rassembler toutes les données existantes qui seront incluses dans la base de données. Établissez ensuite la liste des types de données que vous souhaitez stocker et des entités (personnes, objets, lieux et événements) que ces données décrivent, comme ceci :
Clients
- Nom
- Adresse
- Ville, État, Code postal
- Adresse e-mail
Produits
- Nom
- Prix
- Quantité en stock
- Quantité commandée
Commandes
- ID de la commande
- Commercial
- Date
- Produit(s)
- Quantité
- Prix
- Total
Ces informations feront plus tard partie du dictionnaire de données, qui détaille les tables et les champs de la base de données. Veillez à diviser les informations en éléments les plus petits et les plus utiles possible. Par exemple, pensez à séparer l'adresse de la rue du pays afin de pouvoir ultérieurement filtrer les personnes par pays de résidence. Évitez également de placer la même donnée dans plus d'une table, ce qui ajoute une complexité inutile.
Une fois que vous savez quels types de données la base de données comprendra, d'où elles proviennent et comment elles seront utilisées, vous êtes prêt à planifier la base de données proprement dite.
Structure d'une base de données : les composants essentiels
L'étape suivante consiste à tracer une représentation visuelle de votre base de données. Pour ce faire, vous devez comprendre exactement comment les bases de données relationnelles sont structurées.
Dans une base de données, les données liées sont regroupées en tables, chacune étant constituée de lignes (également appelées tuples) et de colonnes, à l'image d'une feuille de calcul.
Pour convertir vos listes de données en tables, commencez par créer une table pour chaque type d'entité, comme les produits, les ventes, les clients et les commandes. En voici un exemple :
Chaque ligne d'une table est appelée un enregistrement. Les enregistrements contiennent des données sur un objet ou une personne en particulier, comme un client donné. En revanche, les colonnes (également appelées champs ou attributs) contiennent un seul type d'information qui apparaît dans chaque enregistrement, comme l'adresse de tous les clients répertoriés dans la table.
| Prénom | Nom | Âge | Code postal |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Pour garantir la cohérence des données d'un enregistrement à l'autre, attribuez le type de données approprié à chaque colonne. Les types de données les plus courants sont les suivants :
- CHAR - un texte de longueur fixe
- VARCHAR - un texte de longueur variable
- TEXT - de grandes quantités de texte
- INT - un nombre entier positif ou négatif
- FLOAT, DOUBLE - peuvent également stocker des nombres à virgule flottante
- BLOB - des données binaires
Certains systèmes de gestion de bases de données proposent également le type de données Autonumber, qui génère automatiquement un numéro unique dans chaque ligne.
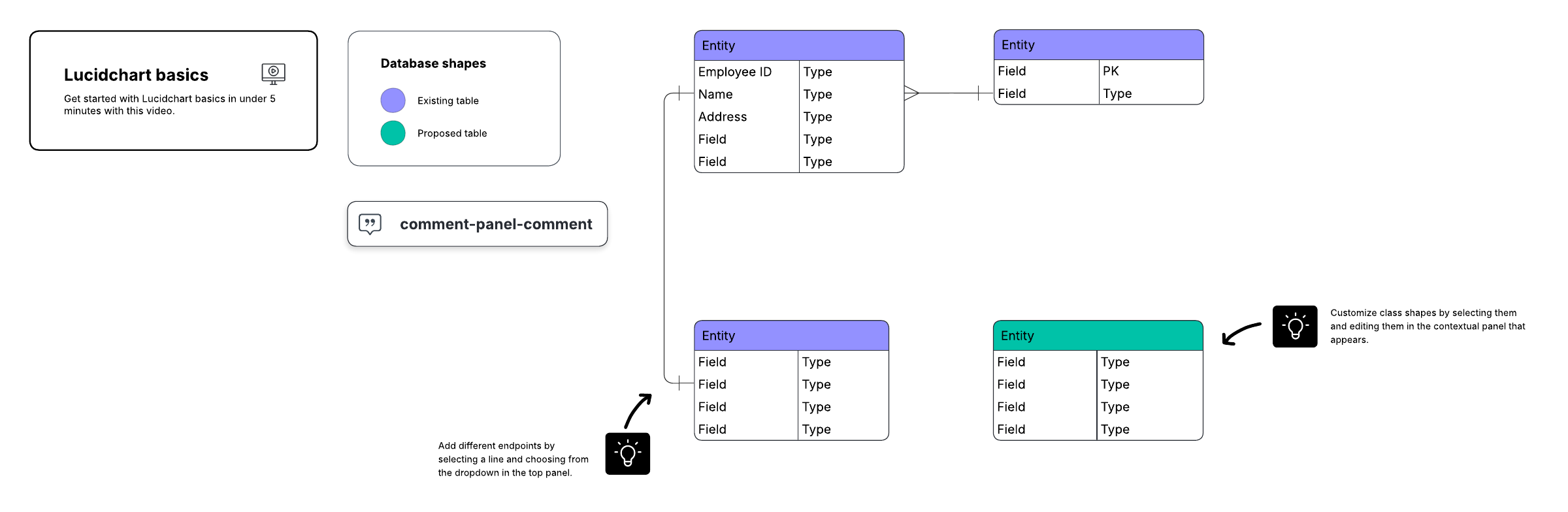
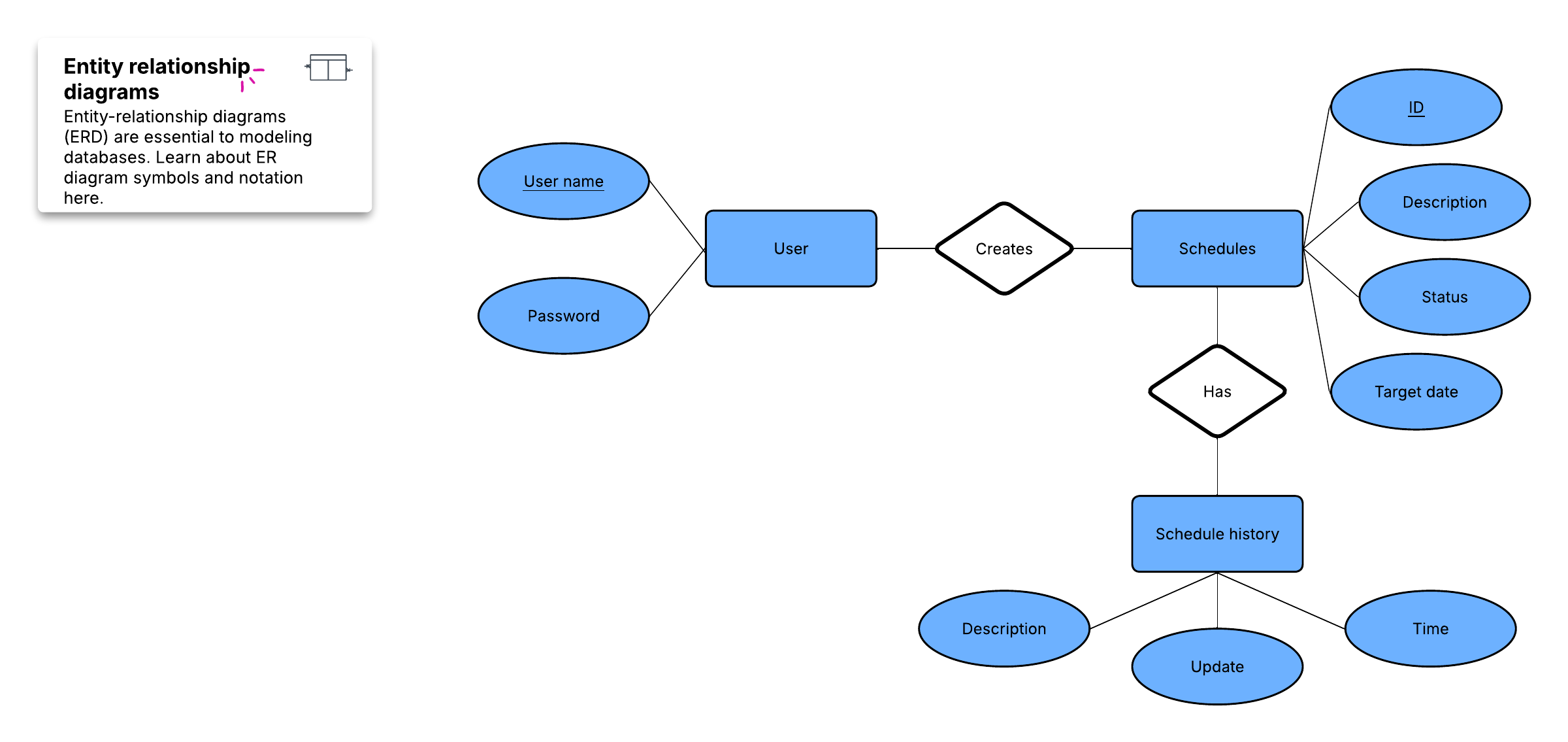
Pour créer un aperçu visuel de la base de données, appelé diagramme entités-associations, vous n'inclurez pas les tables réelles. À la place, chaque table devient une boîte dans le diagramme. Le titre de chaque boîte doit indiquer ce que décrivent les données de cette table, tandis que les attributs sont listés ci-dessous, comme ceci :

Enfin, vous devez décider quel(s) attribut(s) servira(ont) de clé primaire pour chaque table, le cas échéant. Une clé primaire (PK) est un identifiant unique pour une entité donnée, ce qui signifie que vous pouvez identifier un client précis même si vous ne connaissez que cette valeur.
Les attributs choisis comme clés primaires doivent être uniques, immuables et toujours renseignés (jamais NULL ou vides). C'est pourquoi les numéros de commande et les noms d'utilisateur constituent de bonnes clés primaires, contrairement aux numéros de téléphone ou aux adresses postales. Vous pouvez également utiliser plusieurs champs conjointement comme clé primaire (c'est ce que l'on appelle une clé composite).
Au moment de créer la base de données réelle, vous transposerez la structure logique et la structure physique des données dans le langage de définition de données pris en charge par votre système de gestion de base de données. À ce stade, vous devez également estimer la taille de la base de données afin de vous assurer qu'elle offrira le niveau de performance et l'espace de stockage requis.
Création de relations entre les entités
Vos listes de données étant désormais converties en tables, vous pouvez analyser les relations entre ces dernières. La cardinalité fait référence à la quantité d'éléments qui interagissent entre deux tables liées. L'identification de la cardinalité permet de s'assurer que vous avez réparti les données dans les tables de la manière la plus efficace possible.
Chaque entité peut potentiellement avoir une relation avec toutes les autres, mais ces relations sont généralement de trois types :
Relations un à un
Lorsqu'il n'y a qu'une seule instance de l'entité A pour chaque instance de l'entité B, on dit qu'elles ont une relation un à un (souvent écrite 1:1). Vous pouvez indiquer ce type de relation dans un diagramme ER par une ligne terminée par un tiret à chaque extrémité :

Sauf raison majeure, une relation 1:1 indique généralement qu'il serait préférable de combiner les données des deux tables en une seule.
Toutefois, vous pouvez vouloir créer des tables avec une relation 1:1 dans des circonstances particulières. Si vous disposez d'un champ contenant des données facultatives, telles que « description », qui reste vide pour de nombreux enregistrements, vous pouvez déplacer toutes les descriptions dans leur propre table, ce qui élimine les espaces vides et améliore les performances de la base de données.
Pour garantir la correspondance exacte des données, vous devez alors inclure au moins une colonne identique dans chaque table, le plus souvent la clé primaire.
Relations un à plusieurs
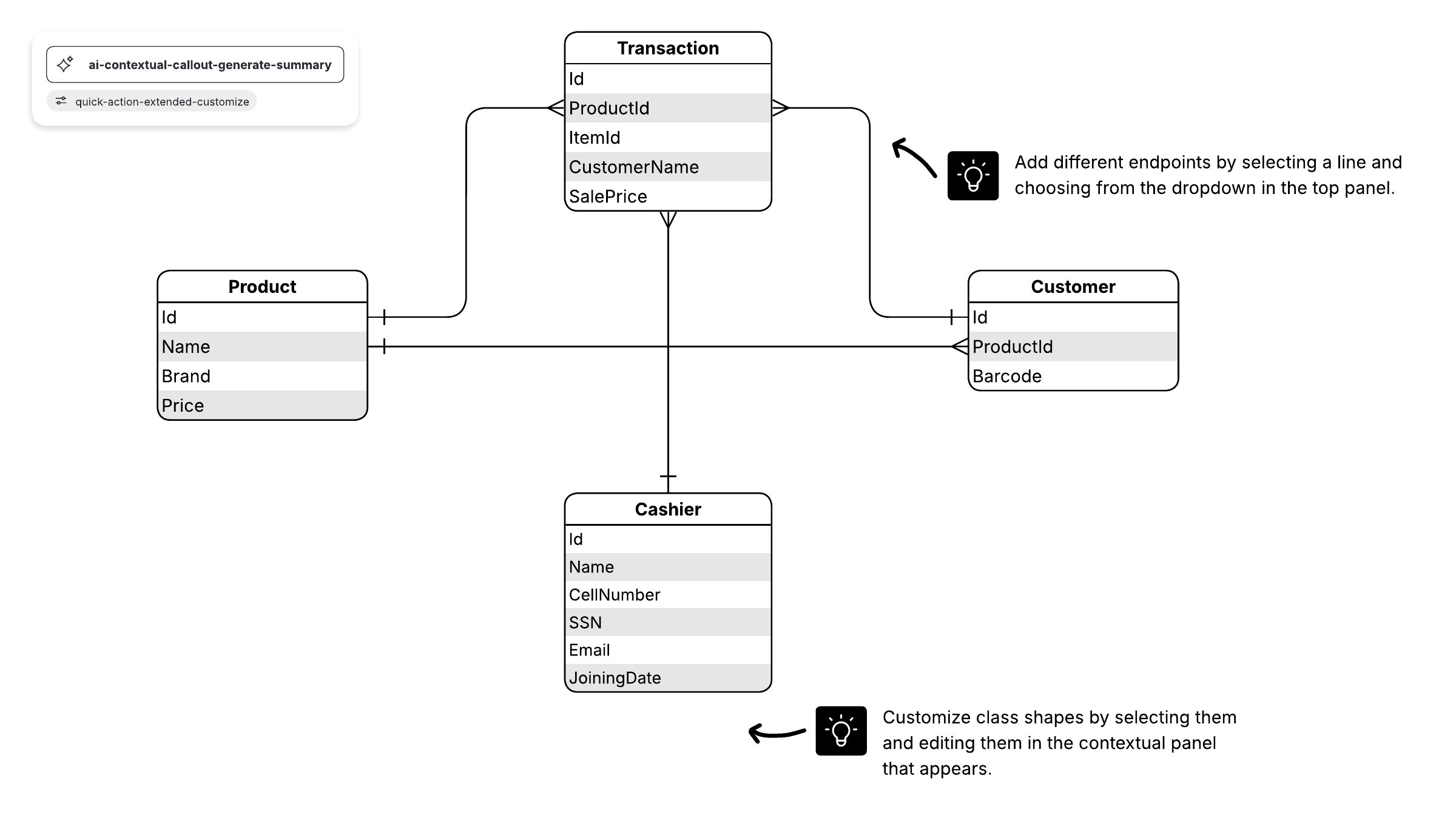
Ces relations surviennent lorsqu'un enregistrement d'une table est associé à plusieurs entrées d'une autre table. Par exemple, un même client peut avoir passé plusieurs commandes, ou un usager peut avoir emprunté plusieurs livres à la bibliothèque en même temps. Les relations un à plusieurs (1:M) sont indiquées par ce que l'on appelle la « notation en patte d'oie », comme dans cet exemple :

Pour mettre en œuvre une relation 1:M lors de la configuration d'une base de données, il suffit d'ajouter la clé primaire du côté « un » de la relation en tant qu'attribut dans l'autre table. Lorsqu'une clé primaire est répertoriée dans une autre table de cette manière, on l'appelle une clé étrangère. La table située du côté « 1 » de la relation est considérée comme la table parente de la table enfant située de l'autre côté.
Relations plusieurs à plusieurs
Lorsque plusieurs entités d'une table peuvent être associées à plusieurs entités d'une autre table, on dit qu'elles ont une relation plusieurs à plusieurs (M:N). Cela peut se produire dans le cas des étudiants et des cours, car un étudiant peut suivre plusieurs cours et un cours peut accueillir plusieurs étudiants.
Dans un diagramme ER, ces relations sont représentées par ces lignes :

Malheureusement, il n'est pas possible de mettre directement en œuvre ce type de relation dans une base de données. Vous devez l'isoler en deux relations un à plusieurs.
Pour ce faire, créez une nouvelle entité entre ces deux tables. Si la relation M:N existe entre les ventes et les produits, vous pouvez appeler cette nouvelle entité « produits_vendus », car elle afficherait le contenu de chaque vente. Les tables des ventes et des produits auraient toutes deux une relation 1:M avec produits_vendus. Ce type d'entité intermédiaire est appelé table de liaison, entité associative ou table de jonction dans différents modèles.
Chaque enregistrement de la table de liaison ferait correspondre deux des entités des tables voisines (il peut également inclure des informations supplémentaires). Par exemple, une table de liaison entre les étudiants et les cours pourrait ressembler à ceci :

Obligatoire ou non ?
Une autre façon d'analyser les relations est de considérer quel côté de la relation doit exister pour que l'autre existe. Le côté non obligatoire peut être marqué par un cercle sur la ligne à l'endroit où se trouverait un tiret. Par exemple, un pays doit exister pour avoir un représentant aux Nations unies, mais l'inverse n'est pas vrai :

Deux entités peuvent être mutuellement dépendantes (l'une ne pourrait pas exister sans l'autre).
Relations récursives
Parfois, une table renvoie à elle-même. Par exemple, une table d'employés peut comporter un attribut « manager » qui fait référence à un autre individu de cette même table. C'est ce qu'on appelle une relation récursive.
Relations redondantes
Une relation redondante est une relation qui s'exprime plus d'une fois. En règle générale, vous pouvez supprimer l'une des relations sans perdre d'informations importantes. Par exemple, si une entité « étudiants » a une relation directe avec une autre entité appelée « enseignants » mais a également une relation indirecte avec les enseignants par le biais des « cours », vous devez supprimer la relation entre « étudiants » et « enseignants ». Il est préférable de supprimer cette relation car la seule façon pour les étudiants d'être affectés à des enseignants est de passer par les cours.
Normalisation de la base de données
Une fois la conception préliminaire de votre base de données établie, vous pouvez appliquer des règles de normalisation pour vous assurer du bon agencement des tables. Considérez ces règles comme les normes du secteur.
Cela dit, toutes les bases de données ne se prêtent pas à la normalisation. En général, les bases de données de traitement de transactions en ligne (OLTP) dans lesquelles les utilisateurs s'occupent de créer, lire, mettre à jour et supprimer des enregistrements doivent être normalisées.
Les bases de données de traitement analytique en ligne (OLAP) qui privilégient l'analyse et le reporting peuvent s'accommoder d'un certain degré de dénormalisation, car l'accent est mis sur la vitesse de calcul. C'est le cas des applications d'aide à la décision dans lesquelles les données doivent être analysées rapidement mais pas modifiées.
Chaque forme, ou niveau de normalisation, inclut les règles associées aux formes inférieures.
Première forme normale
La première forme normale (abrégée en 1NF) spécifie que chaque cellule de la table ne peut contenir qu'une seule valeur, jamais une liste de valeurs. Une table comme celle-ci n'est donc pas conforme :
| ID_produit | Couleur | Prix |
|---|
| 1 | marron, jaune | 15 $ |
| 2 | rouge, vert | 13 $ |
| 3 | bleu, orange | 11 $ |
Vous pourriez être tenté de contourner ce problème en répartissant ces données dans des colonnes supplémentaires, mais cela est également contraire aux règles : une table comportant des groupes d'attributs répétés ou étroitement liés ne respecte pas la première forme normale. La table ci-dessous, par exemple, n'est pas conforme :

Divisez plutôt les données en plusieurs tables ou enregistrements jusqu'à ce que chaque cellule ne contienne qu'une seule valeur et qu'il n'y ait plus de colonnes superflues. À ce stade, les données sont dites atomiques, c'est-à-dire réduites à la plus petite taille utile. Pour la table ci-dessus, vous pourriez créer une table supplémentaire appelée « Détails des ventes » qui associerait des produits spécifiques aux ventes. « Ventes » aurait alors une relation 1:M avec « Détails des ventes ».
Deuxième forme normale
La deuxième forme normale (2NF) exige que chacun des attributs dépende entièrement de l'ensemble de la clé primaire. Cela signifie que chaque attribut doit dépendre directement de la clé primaire, plutôt qu'indirectement par le biais d'un autre attribut.
Par exemple, un attribut « âge » qui dépend de la « date de naissance », laquelle dépend à son tour de l'« ID_étudiant », est considéré comme ayant une dépendance fonctionnelle partielle, et une table contenant ces attributs ne respecterait pas la deuxième forme normale.
En outre, une table dont la clé primaire est composée de plusieurs champs viole la deuxième forme normale si un ou plusieurs autres champs ne dépendent pas de chaque partie de la clé.
Ainsi, une table contenant ces champs ne répondrait pas à la deuxième forme normale, car l'attribut « nom du produit » dépend de l'ID du produit mais pas du numéro de commande :
Troisième forme normale
La troisième forme normale (3NF) ajoute à ces règles l'exigence que chaque colonne n'appartenant pas à la clé soit indépendante de toutes les autres colonnes. Si la modification d'une valeur dans une colonne n'appartenant pas à la clé entraîne la modification d'une autre valeur, cette table ne répond pas à la troisième forme normale.
Cela vous empêche de stocker des données dérivées dans la table, comme la colonne « taxe » ci-dessous, qui dépend directement du prix total de la commande :
| Commande | Prix | Taxe |
| 14325 | 40,99 $ | 2,05 $ |
| 14326 | 13,73 $ | 0,69 $ |
| 14327 | 24,15 $ | 1,21 $ |
D'autres formes de normalisation ont été proposées, notamment la forme normale de Boyce-Codd, les quatrième à sixième formes normales et la forme normale domaine-clé, mais les trois premières sont les plus courantes.
Bien que ces formes expliquent les meilleures pratiques à suivre de manière générale, le degré de normalisation dépend du contexte de la base de données.
Données multidimensionnelles
Certains utilisateurs peuvent vouloir accéder à plusieurs dimensions d'un seul type de data, en particulier dans les bases de données OLAP. Par exemple, ils peuvent vouloir connaître les ventes par client, par État et par mois. Dans ce cas, il est préférable de créer une table de faits centrale à laquelle les autres tables de clients, d'États et de mois peuvent se référer, comme ceci :

Règles d'intégrité des données
Vous devez également configurer votre base de données pour valider les données conformément aux règles appropriées. De nombreux systèmes de gestion de bases de données, comme Microsoft Access, appliquent certaines de ces règles automatiquement.
La règle d'intégrité de l'entité stipule que la clé primaire ne peut jamais être NULL. Si la clé est composée de plusieurs colonnes, aucune d'entre elles ne peut être NULL. Dans le cas contraire, elle pourrait ne pas identifier l'enregistrement de manière unique.
La règle d'intégrité référentielle exige que chaque clé étrangère répertoriée dans une table corresponde à une clé primaire dans la table qu'elle référence. Si la clé primaire change ou est supprimée, ces modifications devront être répercutées partout où cette clé est référencée dans la base de données.
Les règles d'intégrité de la logique métier garantissent que les données correspondent à certains paramètres logiques. Par exemple, l'heure d'un rendez-vous doit se situer dans les heures d'ouverture habituelles.
Ajout d'index et de vues
Un index est essentiellement une copie triée d'une ou plusieurs colonnes, les valeurs étant classées par ordre croissant ou décroissant. L'ajout d'un index permet aux utilisateurs de trouver les enregistrements plus rapidement. Au lieu de procéder à un nouveau tri pour chaque requête, le système peut accéder aux enregistrements dans l'ordre spécifié par l'index.
Bien que les index accélèrent la récupération des données, ils peuvent ralentir l'insertion, la mise à jour et la suppression, car l'index doit être reconstruit chaque fois qu'un enregistrement est modifié.
Une vue est simplement une requête enregistrée sur les données. Elles permettent de joindre utilement des données provenant de plusieurs tables ou d'afficher une partie d'une table.
Propriétés étendues
Une fois la configuration de base terminée, vous pouvez enrichir la base de données avec des propriétés étendues, telles que des textes explicatifs, des masques de saisie et des règles de mise en forme qui s'appliquent à un schéma, une vue ou une colonne en particulier. L'avantage est que, ces règles étant stockées dans la base de données elle-même, la présentation des données sera cohérente d'un programme à l'autre parmi tous ceux qui accèdent aux données.
SQL et UML
Le langage UML (Unified Modeling Language) est une autre méthode visuelle permettant d'exprimer des systèmes complexes créés dans un langage orienté objet. Plusieurs concepts mentionnés dans ce guide portent des noms différents en UML. Par exemple, une entité est appelée une classe en UML.
Le langage UML n'est plus aussi couramment utilisé aujourd'hui qu'auparavant. Il sert désormais surtout dans le cadre universitaire et pour les communications entre les concepteurs de logiciels et leurs clients.
Systèmes de gestion de bases de données
De nombreux choix de conception dépendent du système de gestion de base de données que vous utilisez. Parmi les systèmes les plus courants, on trouve :
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Lorsque vous avez le choix, sélectionnez le système de gestion de base de données approprié en fonction du coût, des systèmes d'exploitation, des fonctionnalités, etc.
Schéma dans le système de base de données Oracle
Dans le système de base de données Oracle, le terme schéma de base de données, également appelé « schéma SQL », a une signification différente. Ici, une base de données peut comporter plusieurs schémas (ou « schemata » pour les puristes). Chacun d'eux contient tous les objets créés par un utilisateur de base de données spécifique. Ces objets peuvent inclonre des tables, des vues, des synonymes, etc. Certains objets ne peuvent pas être inclus dans un schéma, comme les utilisateurs, les contextes, les rôles et les objets de répertoire.

Les utilisateurs peuvent se voir accorder l'accès à des schémas individuels au cas par cas, et la propriété est transférable. Comme chaque objet est associé à un schéma particulier, qui fait office d'espace de noms, il est utile de définir certains synonymes, ce qui permet à d'autres utilisateurs d'accéder à cet objet sans devoir d'abord se référer au schéma auquel il appartient.
Ces schémas n'indiquent pas nécessairement la manière dont les fichiers de données sont stockés physiquement. Les objets de schéma sont stockés logiquement dans un espace de table (tablespace). L'administrateur de la base de données peut spécifier l'espace à allouer à un objet particulier dans un fichier de données.
Enfin, les schémas et les espaces de table ne se superposent pas forcément parfaitement : les objets d'un schéma peuvent se trouver dans plusieurs espaces de table, tandis qu'un espace de table peut inclure des objets provenant de plusieurs schémas.
Instance de base de données ou schéma de base de données ?
Ces termes, bien que liés, ne signifient pas la même chose. Un schéma de base de données est l'ébauche d'une base de données planifiée. Il ne contient pas encore de données réelles.
Une instance de base de données, en revanche, est un instantané d'une base de données telle qu'elle existait à un moment précis. Ainsi, les instances de base de données peuvent changer au fil du temps, tandis qu'un schéma de base de données reste généralement statique, car il est difficile de modifier la structure d'une base de données une fois qu'elle est opérationnelle.
Les schémas de base de données et les instances de base de données peuvent interagir par l'intermédiaire d'un système de gestion de base de données (SGBD). Le SGBD veille à ce que chaque instance de base de données respecte les contraintes imposées par les concepteurs dans le schéma de base de données.
Exigences d'intégration des schémas
Il peut être utile d'intégrer plusieurs sources dans un schéma unique. Veillez à ce que ces exigences soient respectées pour une transition fluide :
Préservation du chevauchement
Chaque élément en chevauchement dans les schémas que vous intégrez doit figurer dans une table de schéma de base de données.
Préservation du chevauchement étendu
Les éléments qui n'apparaissent que dans une seule source, mais qui sont associés à des éléments en chevauchement, doivent être copiés dans le schéma de base de données final.
Normalisation
Les relations et entités indépendantes ne doivent pas être regroupées dans la même table du schéma de base de données.
Minimalité
Idéalement, aucun des éléments des différentes sources ne doit être perdu.
Types de schémas de base de données
Certains modèles se sont développés dans la conception des schémas de base de données.
Le schéma en étoile, très répandu, est aussi le plus simple. Une ou plusieurs tables de faits y sont reliées à un nombre illimité de tables de dimensions. Il est idéal pour gérer des requêtes simples.
Le schéma en flocon, qui s'y rapporte, sert également à représenter une base de données multidimensionnelle. Dans ce modèle, cependant, les dimensions sont normalisées en de nombreuses tables distinctes, ce qui crée l'effet expansif d'une structure en forme de flocon de neige.