要件分析:データベースの目的の明確化
データベースの目的を理解することは、設計プロセス全体における選択に影響を与えます。あらゆる視点からデータベースを検討するようにしてください。例えば、公共図書館のデータベースを作成する場合、利用者と司書の両方がデータにアクセスする必要がある方法を考慮する必要があります。
データベースを作成する前に情報を収集する方法には、以下のようなものがあります:
- 利用する人々へのヒアリング
- 請求書、タイムシート、アンケートなどのビジネスフォームの分析
- 既存のデータシステム(物理ファイルおよびデジタルファイルを含む)の徹底的な調査
まず、データベースに含める既存のデータをすべて収集します。次に、保存したいデータの種類と、それらのデータが表すエンティティ(人、物、場所、イベントなど)を以下のようにリストアップします:
顧客
- 氏名
- 住所
- 市区町村、都道府県、郵便番号
- メールアドレス
製品
注文
- 注文ID
- 担当営業
- 日付
- 製品
- 数量
- 価格
- 合計金額
この情報は後で、データベース内のテーブルとフィールドの概要を示すデータディクショナリの一部となります。情報は必ず利用可能な最小の単位に分解してください。例えば、後で居住国ごとに個人をフィルタリングできるように、住所から国を分けておくことを検討します。また、不必要な複雑さを避けるため、同じデータ項目を複数のテーブルに配置することは避けてください。
データベースにどのようなデータが含まれ、そのデータがどこから来て、どのように使用されるかが分かったら、実際のデータベースの計画を開始する準備は完了です。
データベース構造:データベースの構成要素
次のステップは、データベースの視覚的な表現を配置することです。そのためには、関係データベースがどのように構造化されているかを正確に理解する必要があります。
データベース内では、関連するデータがテーブルにグループ化され、各テーブルはスプレッドシートのように行(タプルとも呼ばれます)と列で構成されます。
データのリストをテーブルに変換するには、まず製品、売上、顧客、注文など、エンティティの種類ごとにテーブルを作成します。以下がその例です:
テーブルの各行はレコードと呼ばれます。レコードには、特定の顧客など、何かまたは誰かに関するデータが含まれます。対照的に、列(フィールドまたは属性とも呼ばれます)には、テーブルにリストされているすべての顧客の住所など、各レコードに表示される単一の種類の情報が含まれます。
| 名前 | 苗字 | 年齢 | 郵便番号 |
|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
レコード間でデータの整合性を保つために、各列に適切なデータ型を割り当てます。一般的なデータ型には以下のものがあります:
- CHAR - 固定長のテキスト
- VARCHAR - 可変長のテキスト
- TEXT - 大容量のテキスト
- INT - 正または負の整数
- FLOAT、DOUBLE - 浮動小数点数も保存可能
- BLOB - バイナリデータ
一部のデータベース管理システムでは、各行に一意の番号を自動的に生成するオートナンバーデータ型も提供されています。
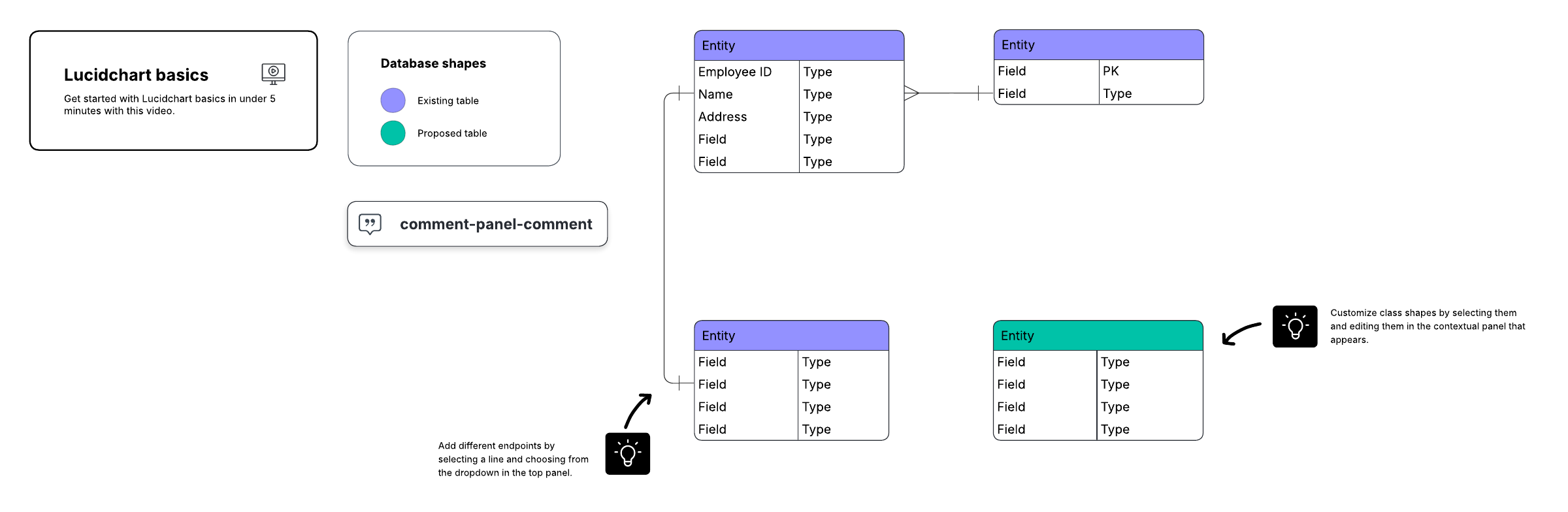
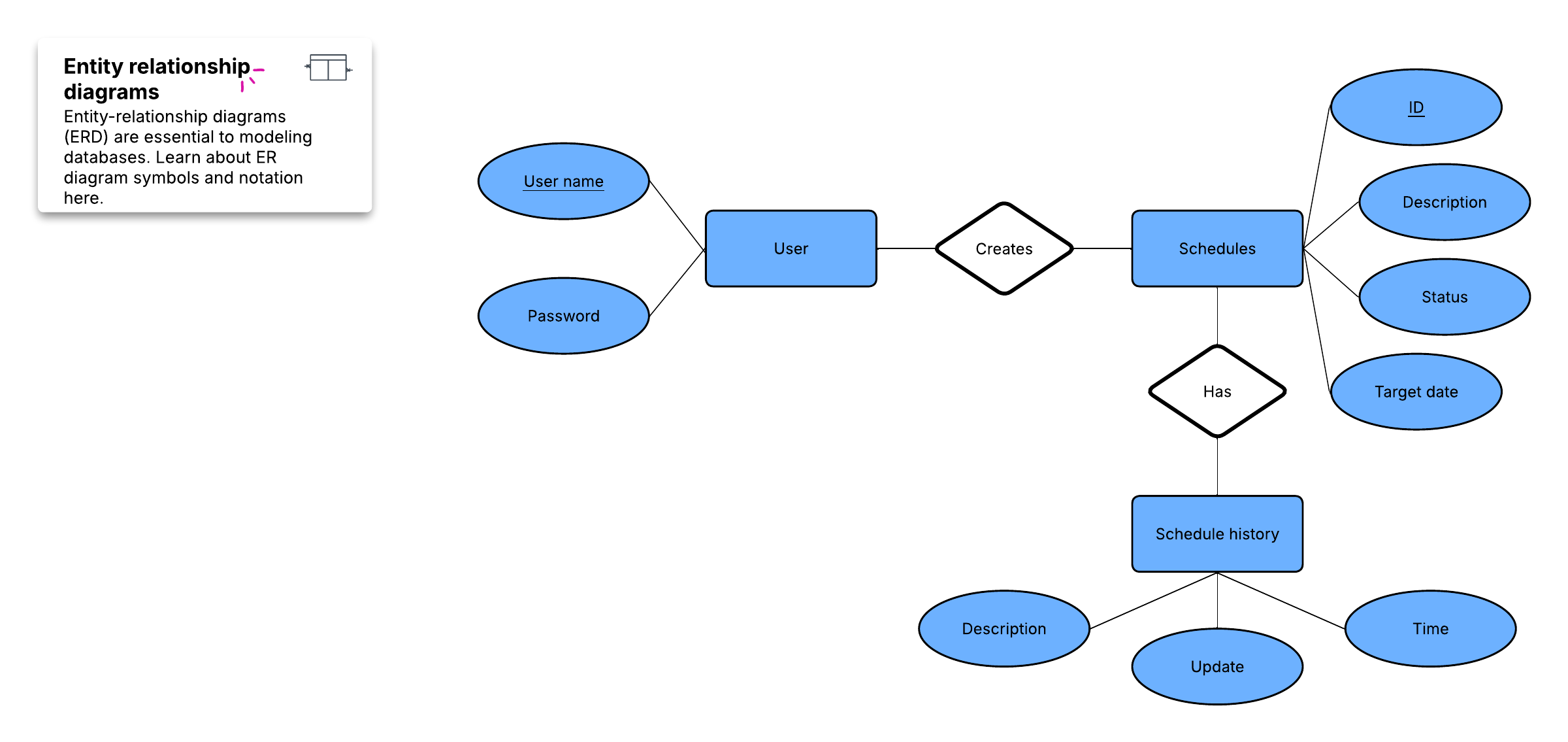
実体関連図(ER図)として知られるデータベースの視覚的な概要を作成する場合、実際のテーブルは含めません。代わりに、各テーブルは図の中のボックスになります。各ボックスのタイトルはそのテーブルのデータが何を表しているかを示し、属性は以下のように下にリストされます:

最後に、各テーブルの主キーとして機能する属性を決定します。主キー(PK)は特定のエンティティの一意の識別子であり、その値さえ分かれば正確な顧客を特定できることを意味します。
主キーとして選択される属性は、一意で、変更されず、常に存在(決してNULLや空ではない)している必要があります。このため、注文番号やユーザー名は適切な主キーになりますが、電話番号や住所は適していません。また、複数のフィールドを組み合わせて主キーとして使用することもできます(これは複合キーと呼ばれます)。
実際のデータベースを作成する段階になったら、論理データ構造と物理データ構造の両方を、データベース管理システムがサポートするデータ定義言語に組み込みます。その時点で、必要なパフォーマンスレベルと記憶容量を確実に確保できるよう、データベースのサイズも見定めておく必要があります。
エンティティ間の関係性の作成
データベースのリストをテーブルに変換したら、それらのテーブル間の関係性を分析する準備が整います。カーディナリティ(多重度)とは、関連する2つのテーブル間で相互作用する要素の数量を指します。カーディナリティを特定することで、データを最も効率的にテーブルに分割できているかを確認できます。
各エンティティは他のすべてのエンティティと関係性を持つ可能性がありますが、それらの関係性は通常、次の3つのタイプのいずれかになります:
1対1の関係
エンティティAのインスタンス1つに対して、エンティティBのインスタンスが1つだけ存在する場合、それらは1対1の関係(1:1と表記されることが多い)にあると言われます。ER図では、両端にダッシュが付いた線でこの種の関係を示すことができます:

特別な理由がない限り、1:1の関係は、2つのテーブルのデータを単一のテーブルに結合した方がよいことを示しているのが一般的です。
ただし、特定の状況下では、1:1の関係を持つテーブルを作成したい場合があります。多くのレコードで空白になっている「説明」などのオプションデータのフィールドがある場合、すべての説明を独自のテーブルに移動することで、空のスペースを排除し、データベースのパフォーマンスを向上させることができます。
データが正確に一致することを保証するには、各テーブルに少なくとも1つの同一の列(通常は主キー)を含める必要があります。
1対多の関係
これらの関係は、一方のテーブルのレコードが、もう一方のテーブルの複数のエントリに関連付けられている場合に発生します。例えば、1人の顧客が多くの注文を行ったり、図書館の利用者が一度に複数の本を借りたりする場合です。1対多(1:M)の関係は、この例のように「鳥の足(クローズフット)記法」と呼ばれるもので示されます:

データベースを設定する際に1:Mの関係を実装するには、関係の「1」の側にある主キーを、もう一方のテーブルの属性として追加するだけです。このように主キーが別のテーブルにリストされる場合、それは外部キーと呼ばれます。関係の「1」の側にあるテーブルは、反対側にある子テーブルに対する親テーブルと見なされます。
多対多の関係
一方のテーブルの複数のエンティティが、もう一方のテーブルの複数のエンティティに関連付けられる場合、それらは多対多(M:N)の関係にあると言われます。学生は多くのクラスを履修でき、クラスには多くの学生が在籍できるため、学生とクラスの場合などにこれが当てはまります。
ER図では、これらの関係は以下の線で描写されます:

残念ながら、この種の関係をデータベースに直接実装することはできません。代わりに、2つの1対多の関係に分解する必要があります。
そのためには、これら2つのテーブルの間に新しいエンティティを作成します。M:Nの関係が売上と製品の間に存在する場合、その新しいエンティティは各売上の内容を示すため、「sold_products」と呼ぶことができます。売上テーブルと製品テーブルの両方が、sold_productsと1:Mの関係を持つことになります。この種の仲介エンティティは、さまざまなモデルでリンクテーブル、連関エンティティ、または中間テーブル(ジャンクションテーブル)と呼ばれます。
リンクテーブルの各レコードは、隣接するテーブルの2つのエンティティを一致させます(補足情報が含まれる場合もあります)。例えば、学生とクラスの間のリンクテーブルは以下のようになります:

必須か任意か?
関係性を分析するもう1つの方法は、関係の一方が存在するためにもう一方が存在しなければならないのはどちらかを考慮することです。必須ではない側は、ダッシュが表示される線の位置に丸印を付けて示すことができます。例えば、国が国連に代表を置くためには国が存在しなければなりませんが、その逆は真ではありません:

2つのエンティティは相互に依存し合うこともあります(一方がなければもう一方も存在できない状態)。
再帰的関係
テーブルが自身を指し示すことがあります。例えば、従業員のテーブルに、同じテーブル内の別の個人を参照する「マネージャー」という属性がある場合です。これは再帰的関係と呼ばれます。
冗長な関係
冗長な関係とは、複数回表現されている関係のことです。通常、重要な情報を失うことなく、関係の1つを削除できます。例えば、「学生」というエンティティが「教師」と呼ばれる別のエンティティと直接的な関係を持っていると同時に、「クラス」を通じて間接的にも教師と関係を持っている場合、学生と教師の間の直接的な関係は削除した方がよいでしょう。学生が教師に割り当てられる唯一の方法はクラスを通じてであるため、その関係は削除するのが適切です。
データベースの正規化
データベースの予備設計が完了したら、正規化ルールを適用してテーブルが正しく構造化されているか確認できます。これらのルールは業界標準と考えてください。
とはいえ、すべてのデータベースが正規化に適しているわけではありません。一般に、ユーザーがレコードの作成、読み取り、更新、削除を行うオンライン取引処理(OLTP)データベースは正規化する必要があります。
分析やレポート作成を優先するオンライン分析処理(OLAP)データベースでは、計算速度が重視されるため、ある程度の非正規化を行う方がうまくいく場合があります。これには、データを迅速に分析する必要があるものの、変更はしない意思決定支援アプリケーションなどが含まれます。
正規化の各形態(段階)には、それより下位の形態に関連するルールが含まれています。
第1正規形
第1正規形(1NF)は、テーブルの各セルに1つの値しか持てず、値のリストは決して持てないことを規定しているため、以下のようなテーブルは準拠していません:
| ProductID | Color | Price |
|---|
| 1 | brown, yellow | $15 |
| 2 | red, green | $13 |
| 3 | blue, orange | $11 |
データを追加の列に分割することでこれを回避したくなるかもしれませんが、それもルール違反です。繰り返しのグループや密接に関連する属性を持つテーブルは、第1正規形を満たしません。例えば、以下のテーブルは準拠していません:

代わりに、各セルに1つの値だけが含まれ、余分な列がなくなるまで、データを複数のテーブルまたはレコードに分割します。その時点で、データは原子性を持つ、つまり実用的な最小サイズに分解されたと言えます。上記のテーブルの場合、特定の製品と売上を一致させる「売上明細」という追加のテーブルを作成できます。「売上」は「売上明細」と1:Mの関係を持つことになります。
第2正規形
第2正規形(2NF)は、各属性が主キー全体に完全に依存していることを義務付けています。つまり、各属性は他の属性を介して間接的に依存するのではなく、主キーに直接依存する必要があります。
例えば、「学生ID」に依存する「生年月日」に、「年齢」という属性が依存している場合、これは部分関数従属があると言われ、これらの属性を含むテーブルは第2正規形を満たせません。
さらに、複数のフィールドで構成される主キーを持つテーブルにおいて、他のフィールドの1つ以上がキーのすべての部分に依存していない場合、第2正規形に違反します。
したがって、以下のフィールドを持つテーブルは第2正規形を満たしません。「製品名」属性は製品IDには依存しますが、注文番号には依存しないためです:
第3正規形
第3正規形(3NF)は、これらのルールに加えて、キー以外のすべての列が他のすべての列から独立しているという要件を追加します。キー以外の列の値を変更することによって別の値が変更される場合、そのテーブルは第3正規形を満たしません。
これにより、以下の「税金」列のように、注文の合計金額に直接依存する派生データをテーブルに保存することを防ぎます:
| Order | Price | Tax |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
ボイスコッド正規形、第4から第6正規形、ドメインキー正規形など、追加の正規形も提案されていますが、最初の3つが最も一般的です。
これらの形態は一般的に従うべきベストプラクティスを説明していますが、正規化の度合いはデータベースの文脈によって異なります。
多次元データ
一部のユーザーは、特にOLAPデータベースにおいて、単一のタイプのデータの複数の次元にアクセスしたい場合があります。例えば、顧客別、都道府県別、月別の売上を知りたい場合などです。この状況では、以下のように、他の顧客、都道府県、月のテーブルが参照できる中央のファクトテーブルを作成するのが最適です:

データ整合性規則
適切な規則に従ってデータを検証するようにデータベースを構成する必要もあります。Microsoft Accessなど、多くのデータベース管理システムは、これらの規則の一部を自動的に適用します。
エンティティ整合性規則では、主キーを決してNULLにすることはできないと規定されています。キーが複数の列で構成されている場合、そのいずれもNULLにすることはできません。そうでない場合、レコードを一意に特定できなくなる可能性があります。
参照整合性規則では、一方のテーブルにリストされている各外部キーが、それが参照するテーブルの1つの主キーと一致している必要があります。主キーが変更または削除された場合、それらの変更はデータベース全体でそのキーが参照されているすべての場所に実装される必要があります。
ビジネスロジック整合性規則は、データが特定の論理的パラメータ内に収まることを保証します。例えば、予約時間は通常の営業時間内に収まる必要があります。
インデックスとビューの追加
インデックスとは、本質的に1つ以上の列のソートされたコピーであり、値は昇順または降順のいずれかになります。インデックスを追加すると、ユーザーはレコードをより迅速に見つけることができます。クエリごとに並べ替える代わりに、システムはインデックスによって指定された順序でレコードにアクセスできます。
インデックスはデータ検索を高速化しますが、レコードが変更されるたびにインデックスを再構築する必要があるため、挿入、更新、削除の速度が低下する可能性があります。
ビューとは、単に保存されたデータへのクエリのことです。複数のテーブルからのデータを便利に結合したり、テーブルの一部を表示したりすることができます。
拡張プロパティ
基本レイアウトが完了したら、特定のスキーマ、ビュー、または列に適用される説明テキスト、入力マスク、書式設定規則などの拡張プロパティを使用して、データベースをブラッシュアップできます。利点として、これらの規則はデータベース自体に保存されるため、データにアクセスする複数のプログラム間でデータの表示方法が一貫することになります。
SQLとUML
統一モデリング言語(UML)は、オブジェクト指向言語で作成された複雑なシステムを表現するもう1つの視覚的な方法です。このガイドで言及されている概念のいくつかは、UMLでは異なる名前で知られています。例えば、エンティティはUMLではクラスとして知られています。
UMLはかつてほど頻繁には使用されていません。現在では、学術的に、またソフトウェア設計者とクライアントとの間のコミュニケーションにおいてよく使用されています。
データベース管理システム
設計上の選択の多くは、どのデータベース管理システムを使用するかによって異なります。最も一般的なシステムには以下のものがあります:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
選択肢がある場合は、コスト、オペレーティングシステム、機能などに基づいて、適切なデータベース管理システムを選択してください。
Oracle Databaseシステムにおけるスキーマ
Oracleデータベースシステムでは、「SQLスキーマ」としても知られるデータベーススキーマという用語の意味が異なります。ここでは、1つのデータベースに複数のスキーマを持つことができます。各スキーマには、特定のデータベースユーザーによって作成されたすべてのオブジェクトが含まれます。それらのオブジェクトには、テーブル、ビュー、シノニムなどが含まれます。ユーザー、コンテキスト、ロール、ディレクトリ群など、一部のオブジェクトはスキーマに含めることができません。

ユーザーにはケースバイケースで個々のスキーマへのログインアクセス権を付与でき、所有権は譲渡可能です。各オブジェクトは、一種の名前空間として機能する特定のスキーマに関連付けられているため、いくつかのシノニムを設定しておくと、他のユーザーがそのオブジェクトが属するスキーマを最初に参照することなくオブジェクトにアクセスできるようになり便利です。
これらのスキーマは、データファイルが物理的に保存される方法を必ずしも示すものではありません。代わりに、スキーマオブジェクトは表領域内に論理的に保存されます。データベース管理者は、データファイル内の特定のオブジェクトに割り当てる容量を指定できます。
最後に、スキーマと表領域は必ずしも完全に一致するわけではありません。1つのスキーマのオブジェクトを複数の表領域で見つけることができる一方で、1つの表領域に複数のスキーマのオブジェクトを含めることができます。
データベースインスタンスかデータベーススキーマか?
これらの用語は関連していますが、同じ意味ではありません。データベーススキーマは、計画されたデータベースの設計図です。実際にはデータは含まれていません。
一方、データベースインスタンスは、ある特定の時点に存在したデータベースのスナップショットです。したがって、データベースインスタンスは時間の経過とともに変化する可能性がありますが、データベーススキーマは通常、データベースが稼働し始めると構造を変更することが難しいため、静的です。
データベーススキーマとデータベースインスタンスは、データベース管理システム(DBMS)を介して相互に影響を与える可能性があります。DBMSは、すべてのデータベースインスタンスがデータベース設計者によってデータベーススキーマに課された制約に準拠していることを保証します。
スキーマ統合の要件
複数のソースを単一のスキーマに統合することは有用です。シームレスな移行のために、以下の要件が満たされていることを確認してください:
重複の保存
統合するスキーマ内のすべての重複する要素は、データベーススキーマのテーブルに存在する必要があります。
拡張された重複の保存
1つのソースにのみ表示されるものの、重複する要素に関連付けられている要素は、結果のデータベーススキーマにコピーされる必要があります。
正規化
独立した関係性やエンティティを、データベーススキーマの同じテーブルに一括して入れてはいけません。
最小性
いずれのソースの要素も失われないことが理想的です。
データベーススキーマの種類
データベーススキーマの設計においては、特定のパターンが発展してきました。
広く使用されているスター型スキーマは、最も単純なものでもあります。これには、1つ以上のファクトテーブルが任意の数のディメンションテーブルにリンクされています。単純なクエリを処理するのに最適です。
関連するスノーフレーク型スキーマも、多次元データベースを表現するために使用されます。ただし、このパターンでは、ディメンションが多数の別々のテーブルに正規化され、雪の結晶のような構造の広がりを作り出します。